V2 Spec & Registry: Declarative Configuration
BaseAttentive v2.2.0 uses a spec / registry / resolver workflow that decouples model description from model construction. This notebook walks through:
BaseAttentiveSpec— backend-neutral model configurationJSON serialisation and reload
BaseAttentiveComponentSpec— selecting component keysComponentRegistry— registering a custom builderassemble_model()— resolving aBaseAttentiveV2AssemblyBaseAttentiveV2— building a trainable model from the spec
Why declarative configuration?
Version-control model configs as plain JSON
Reproduce experiments exactly from a saved spec
Swap backends (
tensorflow/torch/jax) without changing model codeOverride components through registry keys instead of constructor rewrites
Setup
[1]:
# ── v2.2.0 Backend Setup ─────────────────────────────────────────────────────
# BASE_ATTENTIVE_BACKEND must be set *before* importing base_attentive.
# Choose your installed backend: "tensorflow" | "torch" | "jax" | "auto"
import os
os.environ.setdefault("BASE_ATTENTIVE_BACKEND", "tensorflow")
os.environ.setdefault("KERAS_BACKEND", os.environ["BASE_ATTENTIVE_BACKEND"])
import keras # initialise Keras 3 backend before base_attentive
BACKEND = os.environ["BASE_ATTENTIVE_BACKEND"]
print(f"Backend: {BACKEND}")
Backend: tensorflow
[2]:
import json
import pathlib
from dataclasses import replace
import numpy as np
from base_attentive import BaseAttentive, __version__
from base_attentive.config import (
BaseAttentiveArchitectureSpec,
BaseAttentiveComponentSpec,
BaseAttentiveRuntimeSpec,
BaseAttentiveSpec,
normalize_base_attentive_spec,
serialize_base_attentive_spec,
)
from base_attentive.experimental import BaseAttentiveV2
from base_attentive.registry import (
ComponentRegistry,
ModelRegistry,
)
from base_attentive.resolver import (
BackendContext,
BaseAttentiveV2Assembly,
assemble_model,
ensure_backend_registrations,
)
component_registry = ComponentRegistry()
model_registry = ModelRegistry()
backend_context = BackendContext.current(BACKEND)
component_registry, model_registry = (
ensure_backend_registrations(
backend_context=backend_context,
component_registry=component_registry,
model_registry=model_registry,
)
)
print(f"BaseAttentive {__version__} spec imports OK")
print("Resolver backend:", backend_context.name)
BaseAttentive 2.2.0 spec imports OK
Resolver backend: tensorflow
1 — Keyword approach (recap)
The classic keyword approach is fine for quick experiments. Everything shown here also applies to v1-style construction.
[3]:
model_kw = BaseAttentive(
static_input_dim=4,
dynamic_input_dim=8,
future_input_dim=6,
output_dim=2,
forecast_horizon=24,
embed_dim=64,
num_heads=8,
dropout_rate=0.15,
)
print("Keyword model:", model_kw.name)
D:\projects\base-attentive\src\base_attentive\core\base_attentive.py:148: DeprecatedParameterWarning: BaseAttentive: 'static_input_dim' is deprecated since 2.1.0 and will be removed in 3.0.0. Use 'static_dim' instead.
resolved = resolve_deprecated_kwargs(
D:\projects\base-attentive\src\base_attentive\core\base_attentive.py:148: DeprecatedParameterWarning: BaseAttentive: 'dynamic_input_dim' is deprecated since 2.1.0 and will be removed in 3.0.0. Use 'dynamic_dim' instead.
resolved = resolve_deprecated_kwargs(
D:\projects\base-attentive\src\base_attentive\core\base_attentive.py:148: DeprecatedParameterWarning: BaseAttentive: 'future_input_dim' is deprecated since 2.1.0 and will be removed in 3.0.0. Use 'future_dim' instead.
resolved = resolve_deprecated_kwargs(
Keyword model: BaseAttentive
2 — BaseAttentiveSpec
BaseAttentiveSpec is a frozen dataclass that stores the full model configuration. The current schema groups fields as follows:
Group |
Fields |
|---|---|
Required I/O |
|
Capacity |
|
Architecture |
|
Runtime |
|
Output |
|
Backend |
|
Component keys |
|
[4]:
spec = BaseAttentiveSpec(
static_input_dim=4,
dynamic_input_dim=8,
future_input_dim=6,
output_dim=2,
forecast_horizon=24,
embed_dim=64,
hidden_units=96,
attention_heads=8,
dropout_rate=0.15,
head_type="quantile",
quantiles=(0.1, 0.5, 0.9),
backend_name="tensorflow",
architecture=BaseAttentiveArchitectureSpec(
encoder_type="hybrid",
decoder_attention_stack=("cross", "hierarchical"),
feature_processing="dense",
),
runtime=BaseAttentiveRuntimeSpec(
num_encoder_layers=2,
memory_size=64,
multi_scale_agg="last",
),
)
print("spec.embed_dim :", spec.embed_dim)
print("spec.quantiles :", spec.quantiles)
print("spec.backend_name :", spec.backend_name)
print("spec.objective :", spec.objective)
print("spec.attention_lvls :", spec.attention_levels)
spec.embed_dim : 64
spec.quantiles : (0.1, 0.5, 0.9)
spec.backend_name : tensorflow
spec.objective : hybrid
spec.attention_lvls : ('cross', 'hierarchical')
Specs are immutable
Specs are frozen dataclasses — attempting to mutate one raises a FrozenInstanceError. To “modify” a spec, use dataclasses.replace:
[5]:
spec_torch = replace(
spec, backend_name="torch", dropout_rate=0.2
)
print(
"Original backend:",
spec.backend_name,
"dropout:",
spec.dropout_rate,
)
print(
"Modified backend:",
spec_torch.backend_name,
"dropout:",
spec_torch.dropout_rate,
)
Original backend: tensorflow dropout: 0.15
Modified backend: torch dropout: 0.2
3 — JSON Serialisation
Specs serialise to/from plain JSON — no pickles, no framework artefacts.
[6]:
# Serialise to dict -> JSON string
spec_dict = serialize_base_attentive_spec(spec)
spec_json = json.dumps(spec_dict, indent=2)
print(spec_json[:600], "...")
{
"static_input_dim": 4,
"dynamic_input_dim": 8,
"future_input_dim": 6,
"output_dim": 2,
"forecast_horizon": 24,
"embed_dim": 64,
"hidden_units": 96,
"attention_heads": 8,
"layer_norm_epsilon": 1e-06,
"dropout_rate": 0.15,
"activation": "relu",
"backend_name": "tensorflow",
"head_type": "quantile",
"quantiles": [
0.1,
0.5,
0.9
],
"lstm_units": 64,
"attention_units": 32,
"vsn_units": null,
"architecture": {
"encoder_type": "hybrid",
"decoder_attention_stack": [
"cross",
"hierarchical"
],
"feature_processing": "dense"
...
[7]:
# Reload from JSON
reloaded_dict = json.loads(spec_json)
spec_reload = normalize_base_attentive_spec(reloaded_dict)
assert spec_reload.embed_dim == spec.embed_dim
assert spec_reload.quantiles == spec.quantiles
print("Spec round-trip: OK")
print("Reloaded backend:", spec_reload.backend_name)
Spec round-trip: OK
Reloaded backend: tensorflow
[8]:
# Save to file
spec_path = pathlib.Path("model_spec.json")
spec_path.write_text(spec_json)
print(f"Spec saved to: {spec_path.resolve()}")
# Load from file
spec_from_file = normalize_base_attentive_spec(
json.loads(spec_path.read_text())
)
print(
"Loaded from file — embed_dim:", spec_from_file.embed_dim
)
Spec saved to: D:\projects\base-attentive\examples\model_spec.json
Loaded from file — embed_dim: 64
4 — BaseAttentiveComponentSpec
BaseAttentiveComponentSpec stores the registry keys used for each logical part of the model. Instead of passing free-form per-component parameter dictionaries, the current API selects named builders such as "encoder.temporal_self_attention" or "pool.mean".
[9]:
component_keys = BaseAttentiveComponentSpec(
dynamic_encoder="encoder.temporal_self_attention",
future_encoder="encoder.temporal_self_attention",
sequence_pooling="pool.mean",
fusion="fusion.concat",
quantile_head="head.quantile_forecast",
)
spec_with_components = replace(
spec, components=component_keys
)
print(
"Dynamic encoder key:",
spec_with_components.components.dynamic_encoder,
)
print(
"Sequence pool key :",
spec_with_components.components.sequence_pooling,
)
print(
"Quantile head key :",
spec_with_components.components.quantile_head,
)
Dynamic encoder key: encoder.temporal_self_attention
Sequence pool key : pool.mean
Quantile head key : head.quantile_forecast
5 — ComponentRegistry: Registering a Custom Builder
The registry stores builder callables keyed by a backend-neutral string. Below, we register a tiny demo pooling builder into a local registry.
[10]:
def build_demo_last_pool(
*,
context=None,
spec=None,
axis=1,
keepdims=False,
**kwargs,
):
def _pool(x, training=False):
return x[:, -1:, :] if keepdims else x[:, -1, :]
return _pool
print("Custom builder defined")
component_registry.register("pool.demo_last", build_demo_last_pool)
print("Registered pool.demo_last")
Custom builder defined
Registered pool.demo_last
[11]:
## Use the custom component in a spec
spec_custom = replace(
spec_with_components,
components=replace(
spec_with_components.components,
sequence_pooling="pool.demo_last",
),
)
assembly = assemble_model(
"base_attentive.v2",
spec=spec_custom,
backend_context=backend_context,
component_registry=component_registry,
model_registry=model_registry,
)
print("Assembly type :", type(assembly).__name__)
print(
"Custom pool in spec :",
spec_custom.components.sequence_pooling,
)
print(
"Resolved pool type :",
type(assembly.sequence_pool).__name__,
)
Assembly type : BaseAttentiveV2Assembly
Custom pool in spec : pool.demo_last
Resolved pool type : function
[12]:
REGISTRY_KEY = "encoder.residual_bilstm"
def build_residual_bilstm(
*,
context=None,
spec=None,
units=64,
num_layers=1,
name=None,
**kwargs,
):
layers_ns = (
context.layers
if context is not None
and getattr(context, "layers", None) is not None
else BackendContext.current("tensorflow").layers
)
dense_cls = layers_ns.Dense
layer_cls = getattr(layers_ns, "Layer", object)
class ResidualBiLSTM(layer_cls):
def __init__(self, units, num_layers, name=None):
try:
super().__init__(name=name)
except TypeError:
super().__init__()
if name is not None:
self.name = name
self.units = units
self.num_layers = num_layers
self.proj = dense_cls(
units, name=f"{name}_proj" if name else None
)
def call(self, inputs, training=False):
projected = self.proj(inputs)
input_shape = getattr(inputs, "shape", None)
output_shape = getattr(projected, "shape", None)
if input_shape == output_shape:
return projected + inputs
return projected
def get_config(self):
base_config = {}
parent = getattr(super(), "get_config", None)
if callable(parent):
base_config = dict(parent())
base_config.update(
{
"units": self.units,
"num_layers": self.num_layers,
}
)
return base_config
return ResidualBiLSTM(
units=units,
num_layers=num_layers,
name=name,
)
component_registry.register(
key=REGISTRY_KEY,
builder=build_residual_bilstm,
backend="generic",
description="Bidirectional LSTM-style demo encoder with residual projection",
replace=True,
)
print("Registered encoder keys:")
for key in component_registry.list_keys():
if key.startswith("encoder."):
print(" ", key)
Registered encoder keys:
encoder.dynamic_window
encoder.hybrid_multiscale
encoder.residual_bilstm
encoder.temporal_self_attention
[13]:
# Test the builder directly
registration = component_registry.resolve(
REGISTRY_KEY,
backend=backend_context.name,
allow_generic=True,
)
layer = registration.builder(
context=backend_context,
spec=spec_with_components,
units=128,
num_layers=3,
name="test_enc",
)
print("Resolved layer type:", type(layer).__name__)
print("Layer units:", layer.units)
print("Layer depth:", layer.num_layers)
Resolved layer type: ResidualBiLSTM
Layer units: 128
Layer depth: 3
Use the custom encoder in a spec
[14]:
spec_custom = replace(
spec,
components=replace(
spec.components,
dynamic_encoder=REGISTRY_KEY,
future_encoder=REGISTRY_KEY,
),
)
print(
"Custom encoder component type:",
spec_custom.components.dynamic_encoder,
)
Custom encoder component type: encoder.residual_bilstm
6 — Building BaseAttentiveV2 from a Spec
The resolved BaseAttentiveV2Assembly is a low-level view of the components. For normal use, instantiate BaseAttentiveV2 with the same spec and let it manage the assembly internally.
[15]:
model_from_spec = BaseAttentiveV2(
static_input_dim=spec_custom.static_input_dim,
dynamic_input_dim=spec_custom.dynamic_input_dim,
future_input_dim=spec_custom.future_input_dim,
output_dim=spec_custom.output_dim,
forecast_horizon=spec_custom.forecast_horizon,
spec=spec_custom,
backend_name=spec_custom.backend_name,
name="spec_driven_v2",
)
print("Model type :", type(model_from_spec).__name__)
print("Forecast horizon:", model_from_spec.spec.forecast_horizon)
print("Head type :", model_from_spec.spec.head_type)
Model type : BaseAttentiveV2
Forecast horizon: 24
Head type : point
[16]:
# Quick smoke-test: forward pass
B, T, H = 8, 24, 24
x_s = np.random.randn(B, 4).astype("float32")
x_d = np.random.randn(B, T, 8).astype("float32")
x_f = np.random.randn(B, H, 6).astype("float32")
out = model_from_spec([x_s, x_d, x_f])
print("Output shape:", np.array(out).shape)
Output shape: (8, 24, 2)
7 — Inspecting the Assembly
The assembly object exposes the concrete components chosen by the resolver. This is useful for debugging, backend inspection, and custom pipelines.
[17]:
print("Assembled model name :", model_from_spec.name)
print("Embed dim from spec :", spec_custom.embed_dim)
print(
"Encoder key in spec :",
spec_custom.components.dynamic_encoder,
)
print(
"Assembly dataclass :",
BaseAttentiveV2Assembly.__name__,
)
print(
"Sequence pool object :",
type(assembly.sequence_pool).__name__,
)
Assembled model name : spec_driven_v2
Embed dim from spec : 64
Encoder key in spec : encoder.residual_bilstm
Assembly dataclass : BaseAttentiveV2Assembly
Sequence pool object : function
[18]:
print(
"Hidden projection:",
type(assembly.hidden_projection).__name__,
)
print(
"Output head :", type(assembly.output_head).__name__
)
print("Backend context :", assembly.backend_context.name)
Hidden projection: Dense
Output head : MultiDecoder
Backend context : tensorflow
8 — Sharing Specs Across Experiments
A common pattern is to define a base spec and derive per-experiment variants with dataclasses.replace.
[19]:
BASE_SPEC = BaseAttentiveSpec(
static_input_dim=4,
dynamic_input_dim=8,
future_input_dim=6,
output_dim=2,
forecast_horizon=24,
embed_dim=64,
attention_heads=8,
dropout_rate=0.1,
)
# Experiment A: TensorFlow, quantile output
spec_A = replace(
BASE_SPEC,
backend_name="tensorflow",
head_type="quantile",
quantiles=(0.1, 0.5, 0.9),
)
# Experiment B: PyTorch, point output, bigger capacity
spec_B = replace(
BASE_SPEC,
backend_name="torch",
embed_dim=128,
hidden_units=128,
dropout_rate=0.2,
)
# Experiment C: JAX, quantile output
spec_C = replace(
BASE_SPEC,
backend_name="jax",
head_type="quantile",
quantiles=(0.2, 0.5, 0.8),
)
experiment_specs = {"A": spec_A, "B": spec_B, "C": spec_C}
for name, s in experiment_specs.items():
pathlib.Path(f"spec_exp_{name}.json").write_text(
json.dumps(serialize_base_attentive_spec(s), indent=2)
)
print(
f"spec_exp_{name}.json saved — backend={s.backend_name}, "
f"head_type={s.head_type}"
)
spec_exp_A.json saved — backend=tensorflow, head_type=quantile
spec_exp_B.json saved — backend=torch, head_type=point
spec_exp_C.json saved — backend=jax, head_type=quantile
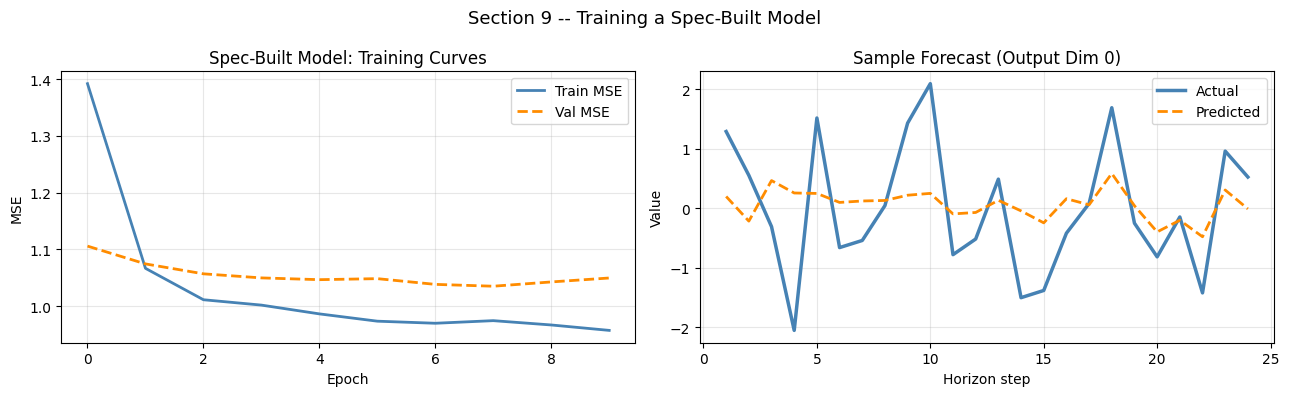
9 — Training a Spec-Built Model
A BaseAttentiveV2 model compiles and trains exactly like any Keras model. Here we train the spec-built model on a small synthetic dataset.
[20]:
import keras
# Synthetic training data
rng = np.random.default_rng(0)
B, T, H = 64, 24, 24
x_s_train = rng.standard_normal((B, 4)).astype('float32')
x_d_train = rng.standard_normal((B, T, 8)).astype('float32')
x_f_train = rng.standard_normal((B, H, 6)).astype('float32')
y_train = rng.standard_normal((B, H, 2)).astype('float32')
# Build a fresh spec-based model for training
train_spec = replace(
BASE_SPEC,
embed_dim=32, attention_heads=4,
)
model_train = BaseAttentive(
static_input_dim=train_spec.static_input_dim,
dynamic_input_dim=train_spec.dynamic_input_dim,
future_input_dim=train_spec.future_input_dim,
output_dim=train_spec.output_dim,
forecast_horizon=train_spec.forecast_horizon,
embed_dim=train_spec.embed_dim,
num_heads=train_spec.attention_heads,
dropout_rate=train_spec.dropout_rate,
name='spec_trained',
)
_ = model_train([x_s_train, x_d_train, x_f_train]) # build weights
model_train.compile(
optimizer=keras.optimizers.Adam(1e-3),
loss='mse', metrics=['mae'],
)
history = model_train.fit(
[x_s_train, x_d_train, x_f_train], y_train,
epochs=10, batch_size=16, validation_split=0.2, verbose=0,
)
print(f'Final train MSE : {history.history["loss"][-1]:.4f}')
print(f'Final val MSE : {history.history["val_loss"][-1]:.4f}')
y_pred = model_train.predict(
[x_s_train, x_d_train, x_f_train], verbose=0)
print(f'Prediction shape: {y_pred.shape}')
Final train MSE : 0.9570
Final val MSE : 1.0494
Prediction shape: (64, 24, 2)
[21]:
import matplotlib.pyplot as plt
fig, axes = plt.subplots(1, 2, figsize=(13, 4))
# Learning curves
ax = axes[0]
ax.plot(history.history['loss'], color='steelblue', lw=2, label='Train MSE')
ax.plot(history.history['val_loss'], color='darkorange', lw=2, linestyle='--', label='Val MSE')
ax.set_title('Spec-Built Model: Training Curves', fontsize=12)
ax.set_xlabel('Epoch'); ax.set_ylabel('MSE')
ax.legend(); ax.grid(True, alpha=0.3)
# Forecast vs actual (sample 0, output dim 0)
ax = axes[1]
steps = np.arange(1, H + 1)
ax.plot(steps, y_train[0, :, 0], color='steelblue', lw=2.5, label='Actual')
ax.plot(steps, y_pred[0, :, 0], color='darkorange', lw=2, linestyle='--', label='Predicted')
ax.set_title('Sample Forecast (Output Dim 0)', fontsize=12)
ax.set_xlabel('Horizon step'); ax.set_ylabel('Value')
ax.legend(); ax.grid(True, alpha=0.3)
plt.suptitle('Section 9 -- Training a Spec-Built Model', fontsize=13)
plt.tight_layout(); plt.show()
10 — Spec vs Keyword: Side-by-Side Comparison
Both BaseAttentive (keyword) and BaseAttentiveV2 (spec) produce equivalent models. The spec approach adds reproducibility and configurability via dataclasses.replace.
[22]:
# Build keyword model
kw_params = dict(
static_input_dim=4, dynamic_input_dim=8,
future_input_dim=6, output_dim=2,
forecast_horizon=24, embed_dim=32, num_heads=4,
dropout_rate=0.1,
)
model_kw2 = BaseAttentive(**kw_params, name='keyword_v')
# Build spec model
cmp_spec = replace(BASE_SPEC, embed_dim=32, attention_heads=4)
model_sp2 = BaseAttentive(
static_input_dim=cmp_spec.static_input_dim,
dynamic_input_dim=cmp_spec.dynamic_input_dim,
future_input_dim=cmp_spec.future_input_dim,
output_dim=cmp_spec.output_dim,
forecast_horizon=cmp_spec.forecast_horizon,
embed_dim=cmp_spec.embed_dim,
num_heads=cmp_spec.attention_heads,
dropout_rate=cmp_spec.dropout_rate,
name='spec_v',
)
# Compare parameter counts
x_s2 = rng.standard_normal((4, 4)).astype('float32')
x_d2 = rng.standard_normal((4, 24, 8)).astype('float32')
x_f2 = rng.standard_normal((4, 24, 6)).astype('float32')
_ = model_kw2([x_s2, x_d2, x_f2])
_ = model_sp2([x_s2, x_d2, x_f2])
kw_params_n = model_kw2.count_params()
sp_params_n = model_sp2.count_params()
print(f'Keyword model params : {kw_params_n:,}')
print(f'Spec model params : {sp_params_n:,}')
print(f'Match: {kw_params_n == sp_params_n}')
Keyword model params : 346,323
Spec model params : 346,323
Match: True
[23]:
# Visual comparison: keyword dict vs spec fields
fig, axes = plt.subplots(1, 2, figsize=(12, 5))
# Left: keyword dict display
ax = axes[0]
ax.axis('off')
kw_text = '\n'.join(
[f'{k} = {v}' for k, v in kw_params.items()]
)
ax.text(0.05, 0.95, 'BaseAttentive(\n ' + kw_text.replace('\n','\n ') + '\n)',
transform=ax.transAxes, fontsize=9, verticalalignment='top',
fontfamily='monospace',
bbox=dict(boxstyle='round', facecolor='#e8f4f8', alpha=0.8))
ax.set_title('Keyword Approach', fontsize=12, pad=10)
# Right: spec fields display
ax = axes[1]
ax.axis('off')
sp_text = (
f'embed_dim = {cmp_spec.embed_dim}\n'
f'attention_heads = {cmp_spec.attention_heads}\n'
f'dropout_rate = {cmp_spec.dropout_rate}\n'
f'forecast_horizon = {cmp_spec.forecast_horizon}\n'
f'static_input_dim = {cmp_spec.static_input_dim}\n'
f'dynamic_input_dim= {cmp_spec.dynamic_input_dim}\n'
f'future_input_dim = {cmp_spec.future_input_dim}\n'
f'output_dim = {cmp_spec.output_dim}'
)
ax.text(0.05, 0.95, 'BaseAttentiveSpec(\n ' + sp_text.replace('\n','\n ') + '\n)',
transform=ax.transAxes, fontsize=9, verticalalignment='top',
fontfamily='monospace',
bbox=dict(boxstyle='round', facecolor='#f0f8e8', alpha=0.8))
ax.set_title('Spec Approach', fontsize=12, pad=10)
plt.suptitle('Section 10 -- Keyword vs Spec: Equivalent Models', fontsize=13)
plt.tight_layout(); plt.show()
print('\nAdvantages of Spec approach:')
print(' * Immutable: prevents accidental mutation')
print(' * JSON-serialisable: saved/reloaded exactly')
print(' * Composable: derive variants with replace()')
print(' * Documented: typed fields with defaults')

Advantages of Spec approach:
* Immutable: prevents accidental mutation
* JSON-serialisable: saved/reloaded exactly
* Composable: derive variants with replace()
* Documented: typed fields with defaults
11 — Registry Inspection & Visualization
ComponentRegistry stores all registered builder functions by string key. Inspecting the registry helps discover available components.
[24]:
# List all registered keys using list_keys()
all_keys = sorted(component_registry.list_keys())
print(f'Total registered components: {len(all_keys)}')
print()
for key in all_keys:
print(f' {key}')
Total registered components: 28
decoder.cross_attention
decoder.hierarchical_attention
decoder.memory_attention
embedding.positional
encoder.dynamic_window
encoder.hybrid_multiscale
encoder.residual_bilstm
encoder.temporal_self_attention
feature.dynamic_processor
feature.future_processor
feature.static_processor
fusion.concat
fusion.multi_resolution_attention
head.multi_horizon
head.point_forecast
head.quantile_distribution
head.quantile_forecast
pool.demo_last
pool.final_flatten
pool.final_last
pool.final_mean
pool.last
pool.mean
projection.dense
projection.dynamic
projection.future
projection.hidden
projection.static
[25]:
# Group keys by prefix (encoder, decoder, etc.)
from collections import defaultdict
groups = defaultdict(list)
for key in sorted(all_keys):
prefix = key.split('.')[0] if '.' in key else 'other'
groups[prefix].append(key)
fig, ax = plt.subplots(figsize=(12, max(4, len(all_keys)*0.35 + 1)))
ax.axis('off')
y = 0.98
colors = ['#3498db','#e67e22','#2ecc71','#9b59b6','#e74c3c','#1abc9c','#f39c12']
for gi, (grp, keys) in enumerate(sorted(groups.items())):
color = colors[gi % len(colors)]
ax.text(0.01, y, grp.upper(), transform=ax.transAxes,
fontsize=10, fontweight='bold', color=color)
y -= 0.05
for key in keys:
ax.text(0.04, y, f' {key}', transform=ax.transAxes,
fontsize=9, fontfamily='monospace', color='#333333')
y -= 0.04
y -= 0.02
ax.set_title('ComponentRegistry: All Registered Keys', fontsize=13, pad=15)
plt.tight_layout(); plt.show()

Summary
Concept |
Purpose |
|---|---|
|
Frozen, JSON-serialisable model blueprint |
|
Declarative selection of component keys |
|
Plug in a custom builder by string key |
|
Resolve a |
|
Trainable resolver-driven model scaffold |
|
Stable JSON export for saved experiments |
|
Derive spec variants without mutation |
|
Inspect all available component keys |
Key Takeaways
Spec = reproducibility: a spec file fully defines the model — no code needed
Keyword approach remains valid for quick prototyping
Spec approach shines for experiment tracking, hyperparameter sweeps, and deployment
The registry is extensible: register any builder function by a string key