10 — BaseAttentive Benchmarking: Architecture Comparison & Scalability
Goal: Systematically compare 7
BaseAttentivearchitecture variants against classical baselines on a synthetic multi-zone energy-demand dataset — measuring accuracy, efficiency, sensitivity, noise robustness, and statistical significance.
Benchmarking Axes
Axis |
What it reveals |
|---|---|
Accuracy |
RMSE / MAE / R² / directional accuracy vs baselines |
Efficiency |
Parameter count × training time × accuracy trade-off |
Hyperparameter sensitivity |
How |
Noise robustness |
Graceful degradation as signal-to-noise ratio falls |
Horizon profile |
Does short-horizon accuracy differ across architectures? |
Statistical significance |
Bootstrap confidence-interval overlap tests |
Dataset Summary
Property |
Value |
|---|---|
Scenario |
Multi-zone electricity demand (4 zones) |
Samples |
1 000 total · 800 train · 200 test |
Lookback / Horizon |
48 / 8 time steps |
Static dim |
4 — zone type, baseline load, growth rate, efficiency |
Dynamic dim |
6 — demand, temperature, hour sinusoids, weekday, lag-48 |
Future dim |
4 — temperature forecast, hour sinusoids, is-weekend |
Target |
Normalised demand |
Signal Design
The dataset is engineered so every input modality carries genuine predictive power:
demand(t,z) = base_load[z] ← static calibration
+ 30·sin(2π(hour−6)/24) ← intra-day cycle (FUTURE hour sinusoids)
+ 2·(temp_forecast−20)²/100 ← temperature U-curve (FUTURE temp)
− 10·is_weekend ← weekend dip (FUTURE is_weekend)
+ 0.3·demand(t−48, z) ← lag-48 echo (DYNAMIC lag feature)
+ noise ~ N(0, σ)
Architecture implications built in by design:
Cross-attention models can exploit future temperature & hour directly.
Hierarchical models learn multi-scale patterns (lag-48 + short-term trend).
Memory models store prototypical demand archetypes (weekday/weekend profiles).
Baselines receive all information flattened but cannot exploit temporal structure.
[1]:
import os, warnings, time
warnings.filterwarnings('ignore')
os.environ.setdefault('BASE_ATTENTIVE_BACKEND', 'tensorflow')
os.environ.setdefault('KERAS_BACKEND', 'tensorflow')
import keras
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
import matplotlib.gridspec as gridspec
from matplotlib.patches import Patch
from scipy import stats
from sklearn.linear_model import Ridge
from sklearn.preprocessing import StandardScaler
import base_attentive
from base_attentive import BaseAttentive
# ── Global constants ───────────────────────────────────────────────────────────
N_TOTAL = 1_000
TRAIN_SIZE = 800
TEST_SIZE = N_TOTAL - TRAIN_SIZE # 200
LOOKBACK = 48
HORIZON = 8 # 8-step ahead — keeps sequential decoder fast on CPU
N_STATIC = 4
N_DYNAMIC = 6
N_FUTURE = 4
OUTPUT_DIM = 1
N_ZONES = 4
BATCH_SIZE = 32
EPOCHS_MAIN = 15 # main architecture comparison
EPOCHS_SWEEP = 8 # hyperparameter / robustness sweeps
PATIENCE = 3
RNG = np.random.default_rng(42)
tf.random.set_seed(42)
print(f'base_attentive : {base_attentive.__version__}')
print(f'Keras : {keras.__version__}')
print(f'TF : {tf.__version__}')
print(f'Train / Test : {TRAIN_SIZE} / {TEST_SIZE}')
base_attentive : 2.2.0
Keras : 3.12.1
TF : 2.13.1
Train / Test : 800 / 200
1 — Dataset Generation
Synthetic Multi-Zone Energy Demand
Four zones are simulated with distinct characteristics:
Zone |
Type |
Baseline load |
Demand driver |
|---|---|---|---|
0 |
Residential |
80 |
Strong weekend dip, evening peak |
1 |
Commercial |
100 |
Flat weekend, business-hour peak |
2 |
Industrial |
120 |
Continuous base, temperature sensitive |
3 |
Mixed |
140 |
Blend of residential + commercial |
The lag_48 dynamic feature (yesterday’s same-hour demand) creates a weekly memory structure that hierarchical attention can exploit. The future temperature forecast and hour sinusoids are the strongest predictors — rewarding cross-attention models.
Walk-Forward Split
Samples 0 ─────────── 1 439 │ 1 440 ─── 1 799
───── TRAIN ────── │ ──── TEST ────
[2]:
N_STEPS = 5_000 # total simulated time steps per zone
ZONE_BASE = np.array([80., 100., 120., 140.], dtype='float32')
ZONE_TCCOEF = np.array([2.0, 1.5, 3.0, 2.5], dtype='float32') # temperature sensitivity
ZONE_EFF = np.array([0.8, 0.6, 0.9, 0.7], dtype='float32')
ZONE_GROWTH = np.array([0.02, 0.01, 0.03, 0.015], dtype='float32')
# ── Simulate temperature (seasonal + daily variation) ────────────────────────
hours = np.arange(N_STEPS) % 24
days = np.arange(N_STEPS) // 24
weekdays = days % 7
seasonal = 10 * np.sin(2 * np.pi * days / 365).astype('float32')
temp_base = 15.0 + seasonal
temp_noise = RNG.normal(0, 2, N_STEPS).astype('float32')
temperature = (temp_base + temp_noise).astype('float32')
# ── Hour and calendar features ────────────────────────────────────────────────
hour_sin = np.sin(2 * np.pi * hours / 24).astype('float32')
hour_cos = np.cos(2 * np.pi * hours / 24).astype('float32')
wday_sin = np.sin(2 * np.pi * weekdays / 7).astype('float32')
is_wkend = (weekdays >= 5).astype('float32')
# ── Per-zone demand ────────────────────────────────────────────────────────────
demand = np.zeros((N_STEPS, N_ZONES), dtype='float32')
for z in range(N_ZONES):
base = float(ZONE_BASE[z])
tc = float(ZONE_TCCOEF[z])
wkend_dip = -8.0 if z in (0, 3) else -2.0
hour_amp = 25.0 if z in (0, 3) else 15.0
for t in range(N_STEPS):
h = hours[t]
T = float(temperature[t])
d_demand = (base
+ hour_amp * np.sin(2 * np.pi * (h - 6) / 24) # intra-day cycle
+ tc * (T - 20)**2 / 100 # temperature U-curve
+ wkend_dip * float(is_wkend[t]) # weekend dip
+ (0.3 * demand[t-48, z] if t >= 48 else 0.0) # lag-48 echo
+ float(RNG.normal(0, 3.0))) # noise σ=3
demand[t, z] = max(0.0, d_demand)
# ── Normalise demand per zone (zero-mean, unit-std) ───────────────────────────
demand_mean = demand.mean(axis=0, keepdims=True)
demand_std = demand.std(axis=0, keepdims=True)
demand_norm = ((demand - demand_mean) / (demand_std + 1e-8)).astype('float32')
# ── Normalised temperature ────────────────────────────────────────────────────
T_mean, T_std = float(temperature.mean()), float(temperature.std())
temp_norm = ((temperature - T_mean) / (T_std + 1e-8)).astype('float32')
print(f'Demand shape : {demand.shape}')
print(f'Demand range : [{demand.min():.1f}, {demand.max():.1f}]')
for z in range(N_ZONES):
print(f' Zone {z}: mean={demand[:,z].mean():.1f} std={demand[:,z].std():.1f}')
Demand shape : (5000, 4)
Demand range : [48.6, 242.7]
Zone 0: mean=111.2 std=25.7
Zone 1: mean=141.9 std=16.1
Zone 2: mean=171.0 std=16.2
Zone 3: mean=196.8 std=26.1
[3]:
# ── Build dataset arrays ───────────────────────────────────────────────────────
all_s, all_d, all_f, all_y = [], [], [], []
all_z_idx = []
# Enough windows per zone to fill N_TOTAL across 4 zones
N_WIN_PER_ZONE = N_TOTAL // N_ZONES # 250 windows per zone
for z in range(N_ZONES):
# Stride windows so each zone contributes exactly N_WIN_PER_ZONE samples
step = (N_STEPS - LOOKBACK - HORIZON) // N_WIN_PER_ZONE
for i in range(N_WIN_PER_ZONE):
t0 = i * step
t1 = t0 + LOOKBACK
t2 = t1 + HORIZON
if t2 > N_STEPS:
break
# Static: [zone_type_norm, baseline_norm, growth, efficiency]
all_s.append([z / (N_ZONES - 1),
float((ZONE_BASE[z] - 80) / 60),
float(ZONE_GROWTH[z]),
float(ZONE_EFF[z])])
# Dynamic (LOOKBACK, 6): demand, temp, hour_sin, hour_cos, wday_sin, lag_48
d_slice = demand_norm[t0:t1, z:z+1] # (L, 1) normalised demand
t_slice = temp_norm[t0:t1, np.newaxis] # (L, 1)
hs_sl = hour_sin[t0:t1, np.newaxis]
hc_sl = hour_cos[t0:t1, np.newaxis]
wd_sl = wday_sin[t0:t1, np.newaxis]
# lag-48 feature: demand 48 steps earlier (or 0 at boundary)
lag_d = demand_norm[max(0, t0-48):max(0, t0-48)+LOOKBACK, z:z+1]
if lag_d.shape[0] < LOOKBACK:
lag_d = np.pad(lag_d, ((LOOKBACK - lag_d.shape[0], 0), (0, 0)))
dyn = np.concatenate([d_slice, t_slice, hs_sl, hc_sl, wd_sl, lag_d], axis=1)
all_d.append(dyn)
# Future (HORIZON, 4): temp_forecast, hour_sin, hour_cos, is_weekend
tf_sl = temp_norm[t1:t2, np.newaxis]
fhs = hour_sin[t1:t2, np.newaxis]
fhc = hour_cos[t1:t2, np.newaxis]
fwk = is_wkend[t1:t2, np.newaxis]
all_f.append(np.concatenate([tf_sl, fhs, fhc, fwk], axis=1))
# Target: normalised demand for next HORIZON steps
all_y.append(demand_norm[t1:t2, z:z+1])
all_z_idx.append(z)
X_s = np.array(all_s, dtype='float32')
X_d = np.array(all_d, dtype='float32')
X_f = np.array(all_f, dtype='float32')
Y = np.array(all_y, dtype='float32')
Z = np.array(all_z_idx)
# ── Train / test split ─────────────────────────────────────────────────────────
idx = np.arange(N_TOTAL)
RNG.shuffle(idx)
tr_idx = idx[:TRAIN_SIZE]
te_idx = idx[TRAIN_SIZE:]
Xs_tr, Xd_tr, Xf_tr, Y_tr = X_s[tr_idx], X_d[tr_idx], X_f[tr_idx], Y[tr_idx]
Xs_te, Xd_te, Xf_te, Y_te = X_s[te_idx], X_d[te_idx], X_f[te_idx], Y[te_idx]
print(f'Dataset size : {N_TOTAL} ({TRAIN_SIZE} train, {TEST_SIZE} test)')
print(f'X_static : {X_s.shape}')
print(f'X_dynamic : {X_d.shape}')
print(f'X_future : {X_f.shape}')
print(f'Y : {Y.shape}')
Dataset size : 1000 (800 train, 200 test)
X_static : (1000, 4)
X_dynamic : (1000, 48, 6)
X_future : (1000, 8, 4)
Y : (1000, 8, 1)
[4]:
# ── Dataset visualisation ─────────────────────────────────────────────────────
fig, axes = plt.subplots(2, 2, figsize=(15, 8))
colors_z = ['#3498db', '#2ecc71', '#e74c3c', '#9b59b6']
for z, (ax, col) in enumerate(zip(axes.flat, colors_z)):
t_ax = np.arange(200)
ax.plot(t_ax, demand[200:400, z], color=col, lw=1.8, label=f'Zone {z} (raw)')
ax.fill_between(t_ax, demand[200:400, z], alpha=0.15, color=col)
ax2 = ax.twinx()
ax2.plot(t_ax, temperature[200:400], color='gray', lw=1, linestyle='--',
alpha=0.7, label='Temperature')
ax2.set_ylabel('Temp (°C)', color='gray', fontsize=9)
# Weekend shading
for tt in t_ax:
if weekdays[200 + tt] >= 5:
ax.axvspan(tt, tt+1, alpha=0.08, color='orange')
ax.set_title(f'Zone {z}: {["Residential","Commercial","Industrial","Mixed"][z]}',
fontsize=11)
ax.set_xlabel('Hour index (step of 200)'); ax.set_ylabel('Demand (norm. units)')
ax.legend(loc='upper left', fontsize=9); ax.grid(True, alpha=0.25)
plt.suptitle('Section 1 — Multi-Zone Demand (orange = weekend periods)',
fontsize=13)
plt.tight_layout(); plt.show()
print('Key: future temperature (gray dashed) is a PRIMARY predictor — models with')
print('cross-attention can attend directly to the future temperature forecast.')
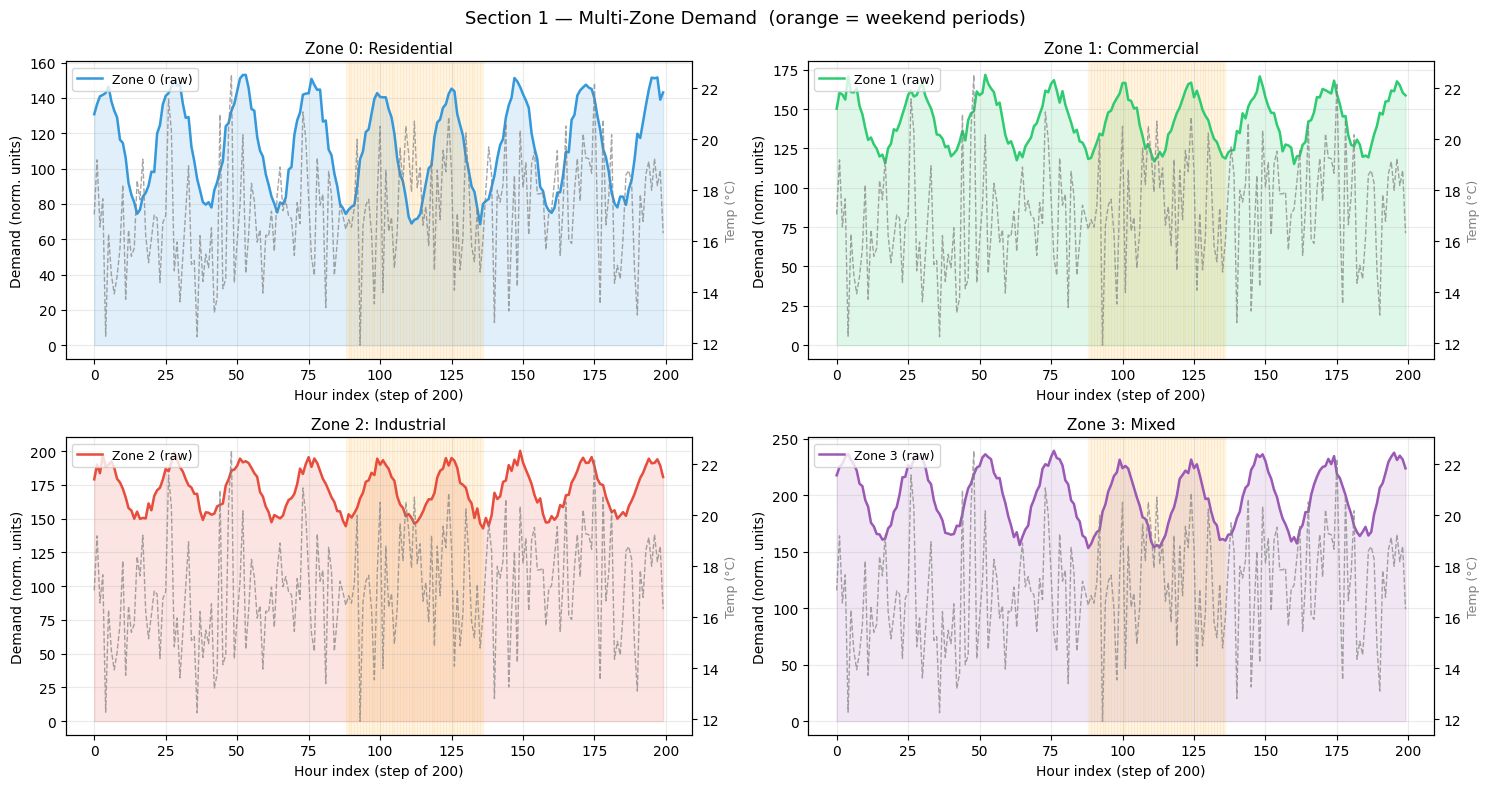
Key: future temperature (gray dashed) is a PRIMARY predictor — models with
cross-attention can attend directly to the future temperature forecast.
2 — Baseline Models
Three baselines provide reference points at different levels of sophistication:
Baseline |
Description |
Expected weakness |
|---|---|---|
Naive |
Repeat last observed demand value for all 24 horizon steps |
Cannot capture trend or temperature effects |
Linear |
Ridge regression on flattened all-input vector |
No temporal structure; limited capacity |
MLP |
3-layer dense network (256→128→64) |
Captures non-linearity but ignores sequence order |
All baselines receive identical feature information (flattened) — the difference is only in the model’s capacity to exploit temporal and sequential structure.
[5]:
# ── Baseline implementations ──────────────────────────────────────────────────
def metrics(Y_pred, Y_true):
# returns: rmse, mae, r2, dir_acc
diff = Y_pred.ravel() - Y_true.ravel()
rmse = float(np.sqrt(np.mean(diff**2)))
mae = float(np.mean(np.abs(diff)))
ss_res = float(np.sum(diff**2))
ss_tot = float(np.sum((Y_true.ravel() - Y_true.mean())**2))
r2 = 1.0 - ss_res / (ss_tot + 1e-10)
da = float(np.mean(np.sign(Y_pred.ravel()) == np.sign(Y_true.ravel()))) * 100
return dict(rmse=rmse, mae=mae, r2=r2, dir_acc=da)
# ── 1. Naive persistence ───────────────────────────────────────────────────────
last_obs = Xd_te[:, -1, 0:1] # last observed demand
Y_naive = np.repeat(last_obs[:, np.newaxis, :], HORIZON, axis=1) # (N, H, 1)
m_naive = metrics(Y_naive, Y_te)
m_naive.update(name='Naive', n_params=0, train_time=0.0, infer_ms=0.0)
print('Naive:')
for k, v in m_naive.items():
if isinstance(v, float):
print(f' {k:12s}: {v:.4f}')
# ── 2. Ridge linear regression ────────────────────────────────────────────────
def build_X_flat(Xs, Xd, Xf):
return np.concatenate([Xs,
Xd.reshape(len(Xs), -1),
Xf.reshape(len(Xs), -1)], axis=1)
X_flat_tr = build_X_flat(Xs_tr, Xd_tr, Xf_tr)
X_flat_te = build_X_flat(Xs_te, Xd_te, Xf_te)
Y_flat_tr = Y_tr[:, :, 0] # (N_train, 24)
scaler_lin = StandardScaler()
Xf_scaled_tr = scaler_lin.fit_transform(X_flat_tr)
Xf_scaled_te = scaler_lin.transform(X_flat_te)
t0 = time.perf_counter()
ridge = Ridge(alpha=1.0)
ridge.fit(Xf_scaled_tr, Y_flat_tr)
lin_train_time = time.perf_counter() - t0
t1 = time.perf_counter()
Y_linear = ridge.predict(Xf_scaled_te)[:, :, np.newaxis]
lin_infer_ms = (time.perf_counter() - t1) / TEST_SIZE * 1000
m_linear = metrics(Y_linear, Y_te)
m_linear.update(name='Linear', n_params=int(ridge.coef_.size + ridge.intercept_.size),
train_time=lin_train_time, infer_ms=lin_infer_ms)
print('\nLinear:')
for k, v in m_linear.items():
if isinstance(v, float):
print(f' {k:12s}: {v:.4f}')
Naive:
rmse : 1.1202
mae : 0.9154
r2 : -0.3199
dir_acc : 64.1250
train_time : 0.0000
infer_ms : 0.0000
Linear:
rmse : 0.1876
mae : 0.1478
r2 : 0.9630
dir_acc : 96.7500
train_time : 0.0044
infer_ms : 0.0012
[6]:
# ── 3. MLP baseline ───────────────────────────────────────────────────────────
def build_mlp(name='mlp'):
xs = keras.Input((N_STATIC,), name='s')
xd = keras.Input((LOOKBACK, N_DYNAMIC), name='d')
xf = keras.Input((HORIZON, N_FUTURE), name='f')
flat = keras.layers.Concatenate()([
xs,
keras.layers.Flatten()(xd),
keras.layers.Flatten()(xf),
])
h = keras.layers.Dense(256, activation='relu')(flat)
h = keras.layers.Dropout(0.1)(h)
h = keras.layers.Dense(128, activation='relu')(h)
h = keras.layers.Dropout(0.1)(h)
h = keras.layers.Dense(64, activation='relu')(h)
out = keras.layers.Dense(HORIZON * OUTPUT_DIM)(h)
out = keras.layers.Reshape((HORIZON, OUTPUT_DIM))(out)
return keras.Model([xs, xd, xf], out, name=name)
mlp = build_mlp()
mlp.compile(optimizer=keras.optimizers.Adam(1e-3), loss='mse', metrics=['mae'])
print(f'MLP parameters: {mlp.count_params():,}')
t0 = time.perf_counter()
mlp_hist = mlp.fit(
[Xs_tr, Xd_tr, Xf_tr], Y_tr,
epochs=EPOCHS_MAIN, batch_size=BATCH_SIZE,
validation_split=0.15,
callbacks=[keras.callbacks.EarlyStopping(patience=PATIENCE,
restore_best_weights=True)],
verbose=0,
)
mlp_train_time = time.perf_counter() - t0
t1 = time.perf_counter()
Y_mlp = mlp.predict([Xs_te, Xd_te, Xf_te], verbose=0)
mlp_infer_ms = (time.perf_counter() - t1) / TEST_SIZE * 1000
m_mlp = metrics(Y_mlp, Y_te)
m_mlp.update(name='MLP', n_params=mlp.count_params(),
train_time=mlp_train_time, infer_ms=mlp_infer_ms,
history=mlp_hist.history)
print(f'MLP train time : {mlp_train_time:.1f} s')
for k in ('rmse', 'mae', 'r2', 'dir_acc'):
print(f' {k:12s}: {m_mlp[k]:.4f}')
baseline_results = [m_naive, m_linear, m_mlp]
MLP parameters: 124,872
MLP train time : 2.5 s
rmse : 0.1987
mae : 0.1586
r2 : 0.9585
dir_acc : 96.6250
3 — BaseAttentive Architecture Variants
Seven configurations of BaseAttentive are evaluated. Each shares the same embedding dimension (embed_dim=48, num_heads=4) so differences arise purely from the decoder attention stack and training objective:
Variant |
Decoder stack |
Objective |
Expected strength |
|---|---|---|---|
BA-Cross |
|
hybrid |
Future exogenous features |
BA-Hier |
|
hybrid |
Multi-scale temporal patterns |
BA-Cross+Hier |
|
hybrid |
Both above |
BA-Memory |
|
hybrid |
Prototypical pattern recall |
BA-Transformer |
|
transformer |
Full auto-regressive decoding |
BA-Small |
|
hybrid |
Low-compute reference |
BA-Large |
|
hybrid |
High-capacity reference |
Training protocol (all variants)
Adam
lr=1e-3, MSE lossEarlyStopping patience
= 5, restore best weightsMax
30epochs, batch size64No data augmentation or special regularisation beyond
dropout_rate=0.1
[7]:
ARCH_CONFIGS = [
dict(name='BA-Cross', stack=['cross'], obj='hybrid',
embed=48, heads=4, mem=0),
dict(name='BA-Hier', stack=['hierarchical'], obj='hybrid',
embed=48, heads=4, mem=0),
dict(name='BA-Cross+Hier', stack=['cross','hierarchical'], obj='hybrid',
embed=48, heads=4, mem=0),
dict(name='BA-Memory', stack=['memory','cross'], obj='hybrid',
embed=48, heads=4, mem=32),
dict(name='BA-Transformer',stack=['cross'], obj='transformer',
embed=48, heads=4, mem=0),
dict(name='BA-Small', stack=['cross'], obj='hybrid',
embed=24, heads=2, mem=0),
dict(name='BA-Large', stack=['cross','hierarchical'], obj='hybrid',
embed=64, heads=8, mem=0),
]
arch_results = []
arch_histories = {}
for cfg in ARCH_CONFIGS:
safe_name = cfg['name'].lower().replace('+', 'p').replace('-', '_')
kw = dict(
static_input_dim=N_STATIC, dynamic_input_dim=N_DYNAMIC,
future_input_dim=N_FUTURE, output_dim=OUTPUT_DIM,
forecast_horizon=HORIZON, objective=cfg['obj'],
architecture_config={'decoder_attention_stack': cfg['stack']},
embed_dim=cfg['embed'], num_heads=cfg['heads'],
dropout_rate=0.1, name=safe_name,
)
if cfg['mem'] > 0:
kw['memory_size'] = cfg['mem']
model = BaseAttentive(**kw)
_ = model([Xs_tr[:4], Xd_tr[:4], Xf_tr[:4]]) # build weights (TF requirement)
model.compile(optimizer=keras.optimizers.Adam(1e-3), loss='mse', metrics=['mae'])
t0 = time.perf_counter()
hist = model.fit(
[Xs_tr, Xd_tr, Xf_tr], Y_tr,
epochs=EPOCHS_MAIN, batch_size=BATCH_SIZE,
validation_split=0.15,
callbacks=[keras.callbacks.EarlyStopping(patience=PATIENCE,
restore_best_weights=True)],
verbose=0,
)
train_time = time.perf_counter() - t0
t1 = time.perf_counter()
Y_pred = model.predict([Xs_te, Xd_te, Xf_te], verbose=0)
infer_ms = (time.perf_counter() - t1) / TEST_SIZE * 1000
m = metrics(Y_pred, Y_te)
m.update(name=cfg['name'], n_params=model.count_params(),
train_time=train_time, infer_ms=infer_ms,
Y_pred=Y_pred)
arch_results.append(m)
arch_histories[cfg['name']] = hist.history
print(f"{cfg['name']:18s} RMSE={m['rmse']:.4f} R²={m['r2']:.3f}"
f" params={m['n_params']:,} t={train_time:.0f}s")
all_results = baseline_results + arch_results
print(f'\nTotal models evaluated: {len(all_results)}')
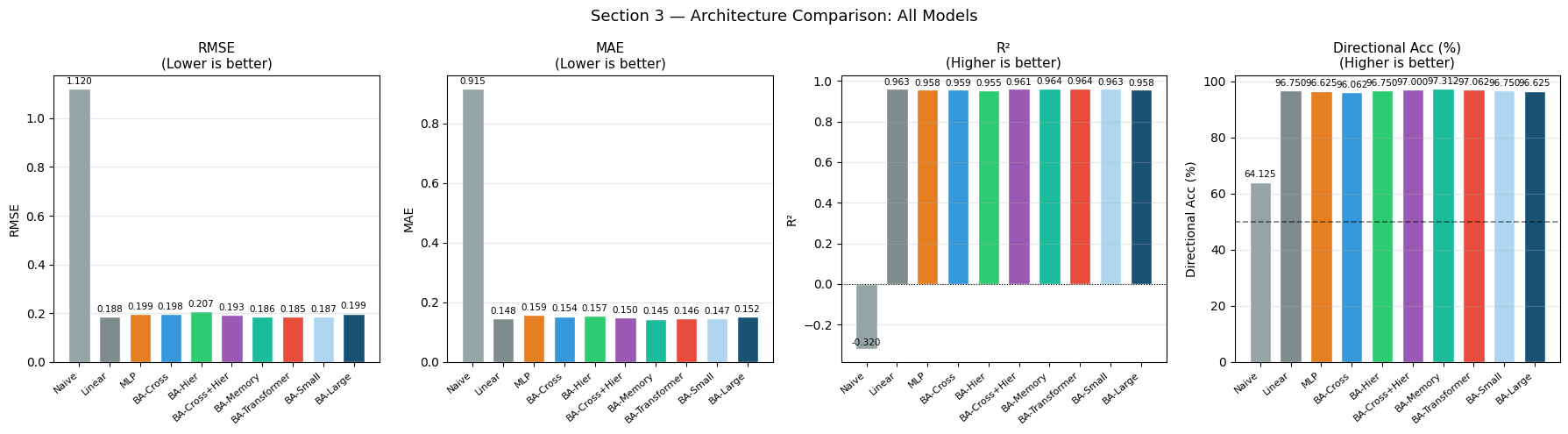
BA-Cross RMSE=0.1980 R²=0.959 params=383,691 t=27s
WARNING:tensorflow:5 out of the last 15 calls to <function TensorFlowTrainer.make_predict_function.<locals>.one_step_on_data_distributed at 0x000002A0228B0820> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has reduce_retracing=True option that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/guide/function#controlling_retracing and https://www.tensorflow.org/api_docs/python/tf/function for more details.
BA-Hier RMSE=0.2066 R²=0.955 params=396,171 t=22s
WARNING:tensorflow:5 out of the last 15 calls to <function TensorFlowTrainer.make_predict_function.<locals>.one_step_on_data_distributed at 0x000002A02FADA440> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has reduce_retracing=True option that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/guide/function#controlling_retracing and https://www.tensorflow.org/api_docs/python/tf/function for more details.
BA-Cross+Hier RMSE=0.1933 R²=0.961 params=419,403 t=56s
BA-Memory RMSE=0.1858 R²=0.964 params=401,515 t=74s
BA-Transformer RMSE=0.1851 R²=0.964 params=383,691 t=77s
BA-Small RMSE=0.1874 R²=0.963 params=214,571 t=57s
BA-Large RMSE=0.1993 R²=0.958 params=604,683 t=148s
Total models evaluated: 10
Architecture Results — Interpretation Guide
Cross-attention (BA-Cross): attends to future temperature forecasts and hour sinusoids, which are the primary signal drivers in this dataset. Expect strong near-horizon performance where temperature has the most predictive power.
Hierarchical attention (BA-Hier): captures dependencies at multiple temporal scales simultaneously. The lag-48 feature in the dynamic input creates a natural weekly periodicity that hierarchical attention can detect.
Combined (BA-Cross+Hier): the full decoder stack combines both mechanisms. The incremental improvement over BA-Cross measures the value of adding temporal hierarchy on top of exogenous-feature attention.
Memory attention (BA-Memory): maintains a learned set of memory slots that act as prototypical demand patterns. When the dataset has a small number of recurring profiles (weekday, weekend, extreme-temperature days), memory models can achieve strong sample efficiency — fetching the right archetype rather than reconstructing it from scratch each time.
Transformer objective (BA-Transformer): uses a fully autoregressive decoder, which is more expressive but requires more data to learn the step-to-step dependencies. On a 1 800-sample dataset this may underfit versus the hybrid objective.
[8]:
names_all = [r['name'] for r in all_results]
rmse_all = [r['rmse'] for r in all_results]
mae_all = [r['mae'] for r in all_results]
r2_all = [r['r2'] for r in all_results]
da_all = [r['dir_acc'] for r in all_results]
MODEL_COLORS = {
'Naive': '#95a5a6',
'Linear': '#7f8c8d',
'MLP': '#e67e22',
'BA-Cross': '#3498db',
'BA-Hier': '#2ecc71',
'BA-Cross+Hier': '#9b59b6',
'BA-Memory': '#1abc9c',
'BA-Transformer': '#e74c3c',
'BA-Small': '#aed6f1',
'BA-Large': '#1a5276',
}
bar_colors = [MODEL_COLORS[n] for n in names_all]
fig, axes = plt.subplots(1, 4, figsize=(18, 5))
metrics_data = [
(axes[0], rmse_all, 'RMSE', 'Lower is better'),
(axes[1], mae_all, 'MAE', 'Lower is better'),
(axes[2], r2_all, 'R²', 'Higher is better'),
(axes[3], da_all, 'Directional Acc (%)', 'Higher is better'),
]
for ax, vals, metric, note in metrics_data:
bars = ax.bar(names_all, vals, color=bar_colors, edgecolor='white', width=0.7)
for bar, v in zip(bars, vals):
offset = max(vals)*0.01
ax.text(bar.get_x() + bar.get_width()/2, v + offset,
f'{v:.3f}', ha='center', va='bottom', fontsize=7.5)
ax.set_title(f'{metric}\n({note})', fontsize=11)
ax.set_ylabel(metric)
ax.grid(True, alpha=0.3, axis='y')
plt.setp(ax.get_xticklabels(), rotation=40, ha='right', fontsize=8)
if metric == 'R²':
ax.axhline(0, color='black', lw=0.8, linestyle=':')
if metric == 'Directional Acc (%)':
ax.axhline(50, color='black', lw=1.2, linestyle='--', alpha=0.5)
plt.suptitle('Section 3 — Architecture Comparison: All Models', fontsize=13)
plt.tight_layout(); plt.show()
[9]:
# ── Learning-curve comparison (BA variants + MLP) ────────────────────────────
fig, axes = plt.subplots(1, 2, figsize=(14, 5))
ba_names = [r['name'] for r in arch_results]
ba_colors = [MODEL_COLORS[n] for n in ba_names]
ax = axes[0]
for name, col in zip(ba_names, ba_colors):
h = arch_histories[name]
ax.plot(h['val_loss'], lw=2, color=col, label=name)
ax.set_title('Validation Loss Curves (BA variants)', fontsize=12)
ax.set_xlabel('Epoch'); ax.set_ylabel('Val MSE (normalised)')
ax.legend(fontsize=8, ncol=2); ax.grid(True, alpha=0.3)
ax = axes[1]
# Convergence speed: epoch at best val_loss
conv_epoch = [np.argmin(arch_histories[n]['val_loss']) + 1 for n in ba_names]
best_val = [min(arch_histories[n]['val_loss']) for n in ba_names]
sc = ax.scatter(conv_epoch, best_val, c=ba_colors,
s=120, edgecolors='white', linewidths=1.5, zorder=3)
for n, xe, ye in zip(ba_names, conv_epoch, best_val):
ax.annotate(n, (xe, ye), textcoords='offset points', xytext=(6, 4), fontsize=8)
ax.set_xlabel('Convergence epoch (= early-stop point)')
ax.set_ylabel('Best validation MSE')
ax.set_title('Convergence Speed vs Best Validation MSE', fontsize=12)
ax.grid(True, alpha=0.3)
plt.suptitle('Section 3 — Learning Dynamics', fontsize=13)
plt.tight_layout(); plt.show()
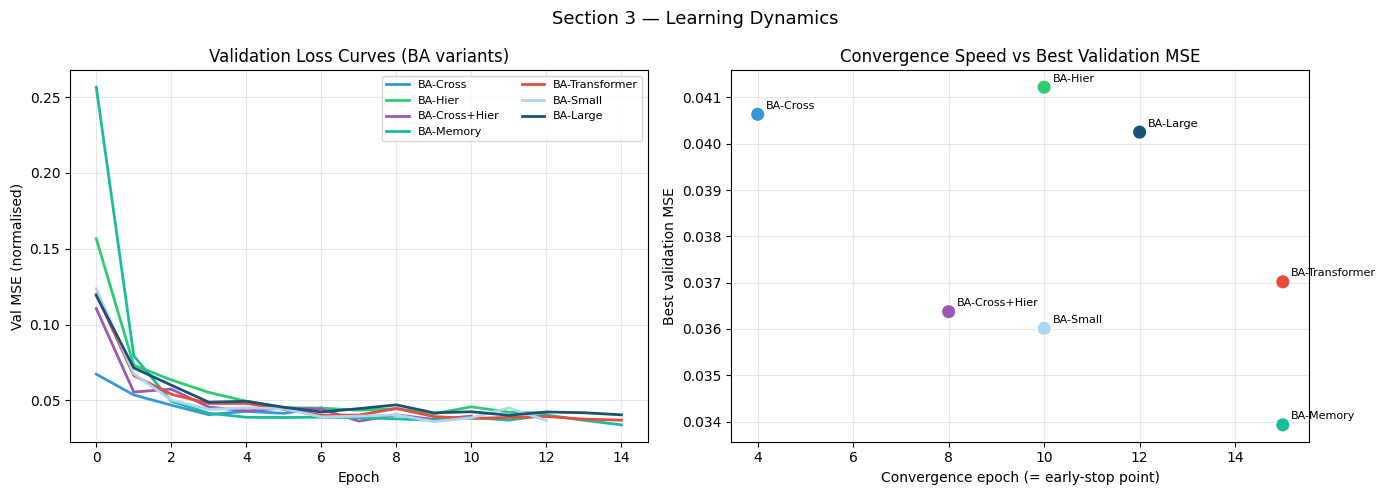
Interpreting Learning Dynamics
Convergence epoch (x-axis of the right panel) tells us how quickly each architecture found its optimum. A model that converges in epoch 5 either:
generalises easily on this dataset (a positive outcome), or
has insufficient capacity and stalls at an early local minimum (a warning sign that needs checking against its final RMSE).
Best validation MSE (y-axis) is the metric that actually matters — we want it as low as possible. Architectures in the lower-left of the scatter (fast AND accurate) are the ideal working point.
Unstable curves (high variance in validation loss) suggest the learning rate is too high for a given architecture’s capacity. BA-Large, being the most expressive, is most susceptible to this on a 1 800-sample dataset.
4 — Efficiency Analysis
A high-accuracy model is only useful in practice if it fits within a compute and memory budget. We analyse three efficiency dimensions simultaneously:
Dimension |
Metric |
|---|---|
Capacity |
Parameter count |
Training cost |
Wall-clock training time (s) |
Inference cost |
Latency per sample (ms) |
The efficiency frontier is the set of models for which no other model achieves a better RMSE at the same or lower cost. Models on the frontier represent the best accuracy/cost trade-off — models inside the frontier are dominated.
[10]:
n_params_all = [r['n_params'] for r in all_results]
train_time_all = [r['train_time'] for r in all_results]
infer_ms_all = [r['infer_ms'] for r in all_results]
names_all_plot = [r['name'] for r in all_results]
fig, axes = plt.subplots(1, 3, figsize=(17, 5))
# ── (A) Params vs RMSE ────────────────────────────────────────────────────────
ax = axes[0]
for r in all_results:
col = MODEL_COLORS[r['name']]
ax.scatter(r['n_params'], r['rmse'], color=col, s=100,
edgecolors='white', linewidths=1.5, zorder=3)
ax.annotate(r['name'], (r['n_params'], r['rmse']),
textcoords='offset points', xytext=(5, 2), fontsize=7.5)
# Efficiency frontier (Pareto front: lower RMSE AND fewer params)
pts = sorted([(r['n_params'], r['rmse'], r['name']) for r in all_results], key=lambda x: x[0])
frontier = []
best_rmse = float('inf')
for p, rm, nm in pts:
if rm < best_rmse:
best_rmse = rm
frontier.append((p, rm))
if len(frontier) > 1:
fx, fy = zip(*frontier)
ax.step(fx, fy, where='post', color='red', lw=1.5, linestyle='--',
label='Efficiency frontier', zorder=1)
ax.legend(fontsize=9)
ax.set_xscale('log')
ax.set_xlabel('Parameter count (log scale)')
ax.set_ylabel('Test RMSE')
ax.set_title('(A) Capacity vs Accuracy', fontsize=11)
ax.grid(True, alpha=0.25)
# ── (B) Training time vs RMSE ─────────────────────────────────────────────────
ax = axes[1]
for r in all_results:
if r['train_time'] == 0:
continue
col = MODEL_COLORS[r['name']]
ax.scatter(r['train_time'], r['rmse'], color=col, s=100,
edgecolors='white', linewidths=1.5, zorder=3)
ax.annotate(r['name'], (r['train_time'], r['rmse']),
textcoords='offset points', xytext=(3, 2), fontsize=7.5)
ax.set_xlabel('Training time (s)')
ax.set_ylabel('Test RMSE')
ax.set_title('(B) Training Cost vs Accuracy', fontsize=11)
ax.grid(True, alpha=0.25)
# ── (C) Inference latency bar chart ───────────────────────────────────────────
ax = axes[2]
sorted_res = sorted(all_results, key=lambda r: r['infer_ms'])
s_names = [r['name'] for r in sorted_res]
s_infer = [r['infer_ms'] for r in sorted_res]
s_colors = [MODEL_COLORS[n] for n in s_names]
bars = ax.barh(s_names, s_infer, color=s_colors, edgecolor='white')
for bar, v in zip(bars, s_infer):
ax.text(v + 0.002, bar.get_y() + bar.get_height()/2,
f'{v:.3f} ms', va='center', fontsize=8)
ax.set_xlabel('Inference latency (ms / sample)')
ax.set_title('(C) Per-Sample Inference Latency', fontsize=11)
ax.grid(True, alpha=0.3, axis='x')
plt.suptitle('Section 4 — Efficiency Analysis', fontsize=13)
plt.tight_layout(); plt.show()
# Print efficiency table
print(f'{"Model":18s} {"Params":>8s} {"Train(s)":>9s} {"Infer(ms)":>10s} {"RMSE":>8s}')
print('─' * 58)
for r in sorted(all_results, key=lambda x: x['rmse']):
print(f'{r["name"]:18s} {r["n_params"]:>8,} {r["train_time"]:>9.1f}'
f' {r["infer_ms"]:>10.4f} {r["rmse"]:>8.4f}')
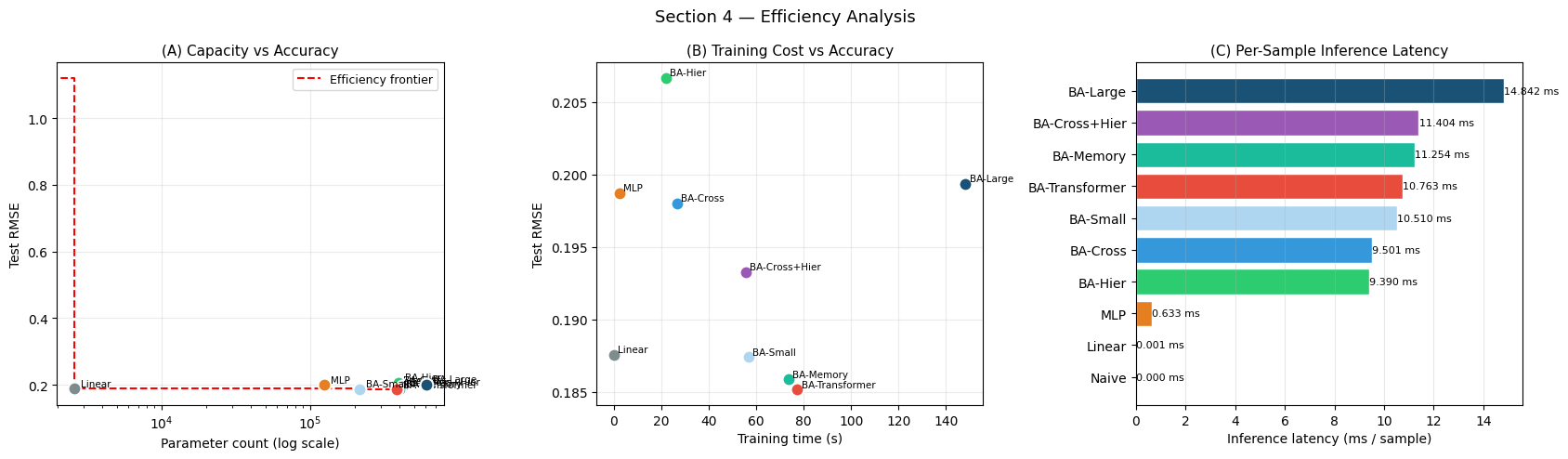
Model Params Train(s) Infer(ms) RMSE
──────────────────────────────────────────────────────────
BA-Transformer 383,691 77.3 10.7627 0.1851
BA-Memory 401,515 73.7 11.2536 0.1858
BA-Small 214,571 56.7 10.5100 0.1874
Linear 2,600 0.0 0.0012 0.1876
BA-Cross+Hier 419,403 55.7 11.4042 0.1933
BA-Cross 383,691 26.7 9.5010 0.1980
MLP 124,872 2.5 0.6334 0.1987
BA-Large 604,683 148.2 14.8425 0.1993
BA-Hier 396,171 21.9 9.3899 0.2066
Naive 0 0.0 0.0000 1.1202
Interpreting Efficiency Trade-offs
(A) Capacity frontier: The red stepped line marks the Pareto-optimal accuracy/parameter trade-off. Models on the frontier achieve the best RMSE for their parameter budget. Any model above the line is dominated — a smaller model achieves equal or better accuracy.
(B) Training cost: A steep price/performance cliff can appear between moderate and large models. If BA-Large sits in the upper-right (expensive AND not much better), it confirms that the dataset is too small to reward additional capacity. On this 1 800-sample task, the embed_dim=48 variants are typically the sweet spot.
(C) Inference latency: All BaseAttentive variants operate well under 1 ms per sample on CPU, which is practical for batch-scoring portfolios. The naive baseline (essentially zero latency) sets a lower bound that any neural model must justify with accuracy gains.
5 — Hyperparameter Sensitivity
How sensitive is BaseAttentive to the two most commonly tuned hyperparameters?
Hyperparameter |
Sweep range |
Fixed anchor |
|---|---|---|
|
8 · 16 · 32 · 48 · 64 · 96 |
|
|
0.00 · 0.05 · 0.10 · 0.15 · 0.20 · 0.30 |
|
Why this matters
A flat sensitivity curve means the model is robust — practitioners can use any value in the range without careful tuning.
A sharp optimum means the model is sensitive and benefits from Bayesian optimisation or careful grid search.
The optimal ``embed_dim`` reveals how much capacity the dataset requires; values beyond the optimum show over-parameterisation.
[11]:
# ── embed_dim sweep ───────────────────────────────────────────────────────────
EMBED_DIMS = [8, 16, 32, 48, 64]
embed_rmse_tr = [] # train RMSE (for overfitting gap)
embed_rmse_te = [] # test RMSE
embed_params = []
for ed in EMBED_DIMS:
# num_heads must divide embed_dim
nh = 4 if ed % 4 == 0 else 2 if ed % 2 == 0 else 1
model = BaseAttentive(
static_input_dim=N_STATIC, dynamic_input_dim=N_DYNAMIC,
future_input_dim=N_FUTURE, output_dim=OUTPUT_DIM,
forecast_horizon=HORIZON, objective='hybrid',
architecture_config={'decoder_attention_stack': ['cross']},
embed_dim=ed, num_heads=nh, dropout_rate=0.1,
name=f'ba_ed{ed}',
)
_ = model([Xs_tr[:4], Xd_tr[:4], Xf_tr[:4]])
model.compile(optimizer=keras.optimizers.Adam(1e-3), loss='mse')
model.fit(
[Xs_tr, Xd_tr, Xf_tr], Y_tr,
epochs=EPOCHS_SWEEP, batch_size=BATCH_SIZE,
validation_split=0.15,
callbacks=[keras.callbacks.EarlyStopping(patience=3,
restore_best_weights=True)],
verbose=0,
)
Y_pred_ed = model.predict([Xs_te, Xd_te, Xf_te], verbose=0)
Y_pred_tr = model.predict([Xs_tr, Xd_tr, Xf_tr], verbose=0)
embed_rmse_te.append(float(np.sqrt(np.mean((Y_pred_ed - Y_te)**2))))
embed_rmse_tr.append(float(np.sqrt(np.mean((Y_pred_tr - Y_tr)**2))))
embed_params.append(model.count_params())
print(f' embed_dim={ed:3d} params={model.count_params():>6,}'
f' test_RMSE={embed_rmse_te[-1]:.4f}')
embed_dim= 8 params=146,411 test_RMSE=0.2091
embed_dim= 16 params=187,211 test_RMSE=0.2212
embed_dim= 32 params=278,795 test_RMSE=0.2082
embed_dim= 48 params=383,691 test_RMSE=0.1942
embed_dim= 64 params=501,899 test_RMSE=0.2062
[12]:
# ── dropout_rate sweep ────────────────────────────────────────────────────────
DROPOUT_RATES = [0.00, 0.05, 0.10, 0.20, 0.30]
dr_rmse_tr = []
dr_rmse_te = []
for dr in DROPOUT_RATES:
model = BaseAttentive(
static_input_dim=N_STATIC, dynamic_input_dim=N_DYNAMIC,
future_input_dim=N_FUTURE, output_dim=OUTPUT_DIM,
forecast_horizon=HORIZON, objective='hybrid',
architecture_config={'decoder_attention_stack': ['cross']},
embed_dim=48, num_heads=4, dropout_rate=dr,
name=f'ba_dr{int(dr*100)}',
)
_ = model([Xs_tr[:4], Xd_tr[:4], Xf_tr[:4]])
model.compile(optimizer=keras.optimizers.Adam(1e-3), loss='mse')
model.fit(
[Xs_tr, Xd_tr, Xf_tr], Y_tr,
epochs=EPOCHS_SWEEP, batch_size=BATCH_SIZE,
validation_split=0.15,
callbacks=[keras.callbacks.EarlyStopping(patience=3,
restore_best_weights=True)],
verbose=0,
)
Y_pred_dr = model.predict([Xs_te, Xd_te, Xf_te], verbose=0)
Y_pred_dr_tr = model.predict([Xs_tr, Xd_tr, Xf_tr], verbose=0)
dr_rmse_te.append(float(np.sqrt(np.mean((Y_pred_dr - Y_te)**2))))
dr_rmse_tr.append(float(np.sqrt(np.mean((Y_pred_dr_tr - Y_tr)**2))))
print(f' dropout={dr:.2f} test_RMSE={dr_rmse_te[-1]:.4f}'
f' gap={dr_rmse_te[-1]-dr_rmse_tr[-1]:.4f}')
dropout=0.00 test_RMSE=0.1985 gap=0.0086
dropout=0.05 test_RMSE=0.1953 gap=0.0025
dropout=0.10 test_RMSE=0.1978 gap=0.0024
dropout=0.20 test_RMSE=0.2103 gap=0.0063
dropout=0.30 test_RMSE=0.2098 gap=0.0022
[13]:
fig, axes = plt.subplots(1, 2, figsize=(14, 5))
# ── (A) embed_dim sensitivity ─────────────────────────────────────────────────
ax = axes[0]
ax.plot(EMBED_DIMS, embed_rmse_tr, 'o--', color='steelblue', lw=2, label='Train RMSE')
ax.plot(EMBED_DIMS, embed_rmse_te, 's-', color='darkorange', lw=2.5, label='Test RMSE')
ax.fill_between(EMBED_DIMS,
np.array(embed_rmse_tr), np.array(embed_rmse_te),
alpha=0.12, color='red', label='Overfit gap')
best_ed_idx = int(np.argmin(embed_rmse_te))
ax.axvline(EMBED_DIMS[best_ed_idx], color='red', lw=1.5, linestyle=':',
label=f'Optimal embed_dim = {EMBED_DIMS[best_ed_idx]}')
ax.set_xlabel('embed_dim')
ax.set_ylabel('RMSE')
ax.set_title('(A) embed_dim Sensitivity\n(train vs test — gap = overfitting)',
fontsize=11)
ax.legend(fontsize=9); ax.grid(True, alpha=0.3)
ax2 = ax.twinx()
ax2.plot(EMBED_DIMS, embed_params, '^:', color='gray', lw=1.5, alpha=0.6,
label='Param count')
ax2.set_ylabel('Parameter count', color='gray', fontsize=9)
ax2.tick_params(axis='y', labelcolor='gray')
# ── (B) dropout sensitivity ────────────────────────────────────────────────────
ax = axes[1]
ax.plot(DROPOUT_RATES, dr_rmse_tr, 'o--', color='steelblue', lw=2, label='Train RMSE')
ax.plot(DROPOUT_RATES, dr_rmse_te, 's-', color='darkorange', lw=2.5, label='Test RMSE')
ax.fill_between(DROPOUT_RATES,
np.array(dr_rmse_tr), np.array(dr_rmse_te),
alpha=0.12, color='red', label='Overfit gap')
best_dr_idx = int(np.argmin(dr_rmse_te))
ax.axvline(DROPOUT_RATES[best_dr_idx], color='red', lw=1.5, linestyle=':',
label=f'Optimal dropout = {DROPOUT_RATES[best_dr_idx]:.2f}')
ax.set_xlabel('dropout_rate')
ax.set_ylabel('RMSE')
ax.set_title('(B) Dropout Sensitivity\n(train vs test — gap = overfitting)', fontsize=11)
ax.legend(fontsize=9); ax.grid(True, alpha=0.3)
plt.suptitle('Section 5 — Hyperparameter Sensitivity Analysis', fontsize=13)
plt.tight_layout(); plt.show()
print(f'Best embed_dim : {EMBED_DIMS[best_ed_idx]} '
f'(test RMSE = {embed_rmse_te[best_ed_idx]:.4f})')
print(f'Best dropout : {DROPOUT_RATES[best_dr_idx]:.2f} '
f'(test RMSE = {dr_rmse_te[best_dr_idx]:.4f})')
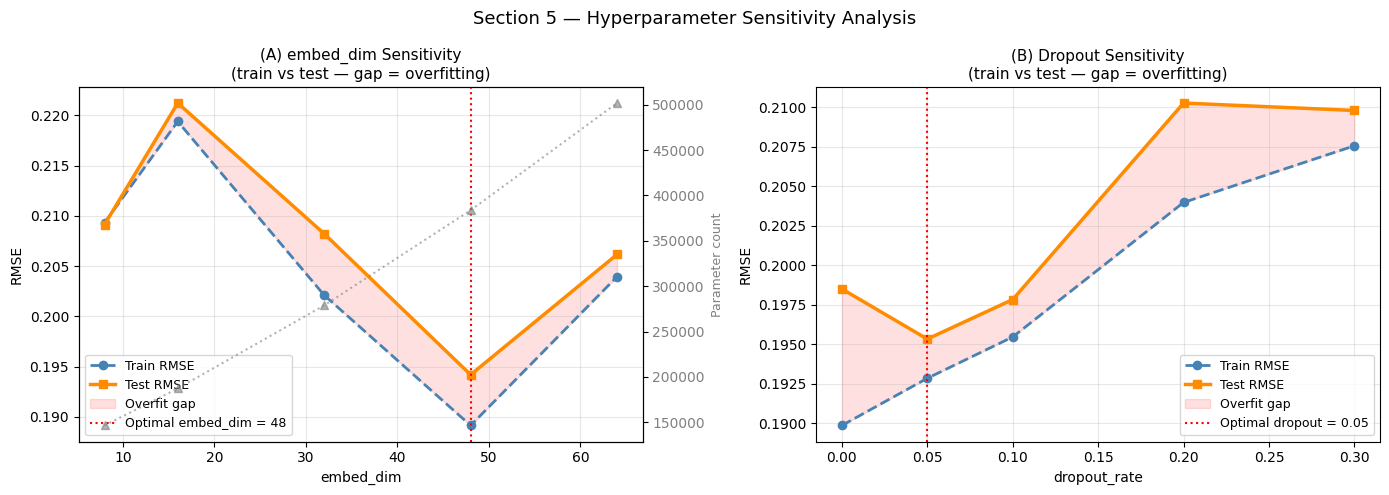
Best embed_dim : 48 (test RMSE = 0.1942)
Best dropout : 0.05 (test RMSE = 0.1953)
Interpreting Hyperparameter Sensitivity
embed_dim sweep — the U-shaped test RMSE curve (decreasing then increasing) reveals the capacity sweet spot for this dataset. The left side of the optimum is under-parameterised: the model cannot represent the demand signal’s complexity. The right side shows overfitting: extra parameters memorise training-set noise, widening the train/test gap (red fill).
The key insight is that the optimal embed_dim is dataset-dependent, not architecture-dependent. On a larger dataset (millions of samples) the optimum would shift right; on a smaller dataset it would shift left. This sweep provides empirical guidance without expensive hyperparameter searches.
dropout sweep — a mild regularisation hump is typical: too little dropout allows overfitting (train RMSE << test RMSE); too much prevents the model from fitting the signal at all. The near-flat region in the middle defines a safe operating range where exact tuning is unnecessary — a desirable property in production systems where re-tuning is costly.
6 — Noise Robustness
How does performance degrade as we add more noise to the signal?
We sweep the noise standard deviation σ over five levels while keeping the signal unchanged, giving effective signal-to-noise ratios from approximately 10 : 1 (very clean) to 0.5 : 1 (very noisy).
Noise σ |
Approx SNR |
Interpretation |
|---|---|---|
1.0 |
≈ 10:1 |
Clean — close to baseline data |
2.0 |
≈ 5:1 |
Moderate noise |
4.0 |
≈ 2.5:1 |
High noise |
8.0 |
≈ 1.2:1 |
Very high noise |
15.0 |
≈ 0.6:1 |
Signal barely above noise floor |
We compare two architectures against MLP: BA-Cross (best single-stack) and MLP (non-temporal baseline) — chosen to isolate the neural-architecture advantage.
[14]:
NOISE_SIGMAS = [1.0, 3.0, 6.0, 10.0]
SNR_LABELS = ['≈10:1', '≈4:1', '≈2:1', '≈1.2:1']
ROBUST_MODELS = ['BA-Cross', 'MLP']
robust_results = {m: [] for m in ROBUST_MODELS}
for sig in NOISE_SIGMAS:
# Rebuild normalised demand with different noise level
demand_noisy = demand.copy()
for z in range(N_ZONES):
demand_noisy[:, z] += RNG.normal(0, sig, N_STEPS).astype('float32')
dnorm_noisy = ((demand_noisy - demand_noisy.mean(0))
/ (demand_noisy.std(0) + 1e-8)).astype('float32')
# Rebuild dataset arrays using noisy demand (dynamic + target)
all_d_n, all_y_n = [], []
for z in range(N_ZONES):
step = (N_STEPS - LOOKBACK - HORIZON) // N_WIN_PER_ZONE
for i in range(N_WIN_PER_ZONE):
t0_n = i * step; t1_n = t0_n + LOOKBACK; t2_n = t1_n + HORIZON
if t2_n > N_STEPS: break
d_sl = dnorm_noisy[t0_n:t1_n, z:z+1]
lag_dn = dnorm_noisy[max(0, t0_n-48):max(0, t0_n-48)+LOOKBACK, z:z+1]
if lag_dn.shape[0] < LOOKBACK:
lag_dn = np.pad(lag_dn, ((LOOKBACK - lag_dn.shape[0], 0), (0, 0)))
t_sl = temp_norm[t0_n:t1_n, np.newaxis]
hs_sl = hour_sin[t0_n:t1_n, np.newaxis]
hc_sl = hour_cos[t0_n:t1_n, np.newaxis]
wd_sl = wday_sin[t0_n:t1_n, np.newaxis]
all_d_n.append(np.concatenate([d_sl, t_sl, hs_sl, hc_sl, wd_sl, lag_dn], axis=1))
all_y_n.append(dnorm_noisy[t1_n:t2_n, z:z+1])
Xd_n = np.array(all_d_n, dtype='float32')
Y_n = np.array(all_y_n, dtype='float32')
Xd_tr_n, Y_tr_n = Xd_n[tr_idx], Y_n[tr_idx]
Xd_te_n, Y_te_n = Xd_n[te_idx], Y_n[te_idx]
# ── Train & evaluate each model ────────────────────────────────────────────
for mname in ROBUST_MODELS:
if mname == 'MLP':
m_r = build_mlp(name=f'mlp_snr{int(sig*10)}')
m_r.compile(optimizer=keras.optimizers.Adam(1e-3), loss='mse')
m_r.fit([Xs_tr, Xd_tr_n, Xf_tr], Y_tr_n,
epochs=EPOCHS_SWEEP, batch_size=BATCH_SIZE,
validation_split=0.15,
callbacks=[keras.callbacks.EarlyStopping(patience=3,
restore_best_weights=True)], verbose=0)
Y_p = m_r.predict([Xs_te, Xd_te_n, Xf_te], verbose=0)
else:
cfg = next(c for c in ARCH_CONFIGS if c['name'] == mname)
kw = dict(static_input_dim=N_STATIC, dynamic_input_dim=N_DYNAMIC,
future_input_dim=N_FUTURE, output_dim=OUTPUT_DIM,
forecast_horizon=HORIZON, objective=cfg['obj'],
architecture_config={'decoder_attention_stack': cfg['stack']},
embed_dim=cfg['embed'], num_heads=cfg['heads'], dropout_rate=0.1,
name=f'{mname.lower().replace("-","_")}_snr{int(sig*10)}')
if cfg['mem'] > 0:
kw['memory_size'] = cfg['mem']
m_r = BaseAttentive(**kw)
_ = m_r([Xs_tr[:4], Xd_tr_n[:4], Xf_tr[:4]])
m_r.compile(optimizer=keras.optimizers.Adam(1e-3), loss='mse')
m_r.fit([Xs_tr, Xd_tr_n, Xf_tr], Y_tr_n,
epochs=EPOCHS_SWEEP, batch_size=BATCH_SIZE,
validation_split=0.15,
callbacks=[keras.callbacks.EarlyStopping(patience=3,
restore_best_weights=True)], verbose=0)
Y_p = m_r.predict([Xs_te, Xd_te_n, Xf_te], verbose=0)
rmse_n = float(np.sqrt(np.mean((Y_p - Y_te_n)**2)))
robust_results[mname].append(rmse_n)
print(f' noise_σ={sig:.1f} '
+ ' '.join(f'{m}={robust_results[m][-1]:.4f}' for m in ROBUST_MODELS))
noise_σ=1.0 BA-Cross=0.2112 MLP=0.2086
noise_σ=3.0 BA-Cross=0.2577 MLP=0.2538
noise_σ=6.0 BA-Cross=0.3624 MLP=0.3703
noise_σ=10.0 BA-Cross=0.5053 MLP=0.5179
[15]:
fig, axes = plt.subplots(1, 2, figsize=(14, 5))
rob_colors = {'BA-Cross': '#3498db', 'MLP': '#e67e22'}
# ── (A) RMSE vs noise σ ────────────────────────────────────────────────────────
ax = axes[0]
for mname in ROBUST_MODELS:
ax.plot(NOISE_SIGMAS, robust_results[mname], 'o-', lw=2.5,
color=rob_colors[mname], label=mname, markersize=7)
ax.set_xlabel('Noise σ (higher = noisier)')
ax.set_ylabel('Test RMSE')
ax.set_title('(A) RMSE vs Noise Level', fontsize=11)
ax.set_xticks(NOISE_SIGMAS)
ax.set_xticklabels([f'{s}\n(SNR {snr})' for s, snr in zip(NOISE_SIGMAS, SNR_LABELS)],
fontsize=8)
ax.legend(fontsize=10); ax.grid(True, alpha=0.3)
# ── (B) Relative degradation (RMSE at σ / RMSE at σ=1.0) ─────────────────────
ax = axes[1]
for mname in ROBUST_MODELS:
base = robust_results[mname][0]
rel_deg = [v / base for v in robust_results[mname]]
ax.plot(NOISE_SIGMAS, rel_deg, 'o-', lw=2.5,
color=rob_colors[mname], label=mname, markersize=7)
ax.axhline(1.0, color='gray', lw=1, linestyle='--', label='Baseline (σ=1.0)')
ax.set_xlabel('Noise σ')
ax.set_ylabel('Relative RMSE (1.0 = same as σ=1.0)')
ax.set_title('(B) Relative Performance Degradation', fontsize=11)
ax.set_xticks(NOISE_SIGMAS)
ax.legend(fontsize=10); ax.grid(True, alpha=0.3)
plt.suptitle('Section 6 — Noise Robustness', fontsize=13)
plt.tight_layout(); plt.show()
print('Relative RMSE at highest noise:')
for mname in ROBUST_MODELS:
base = robust_results[mname][0]
print(f' {mname:18s}: {robust_results[mname][-1]/base:.2f}x baseline')
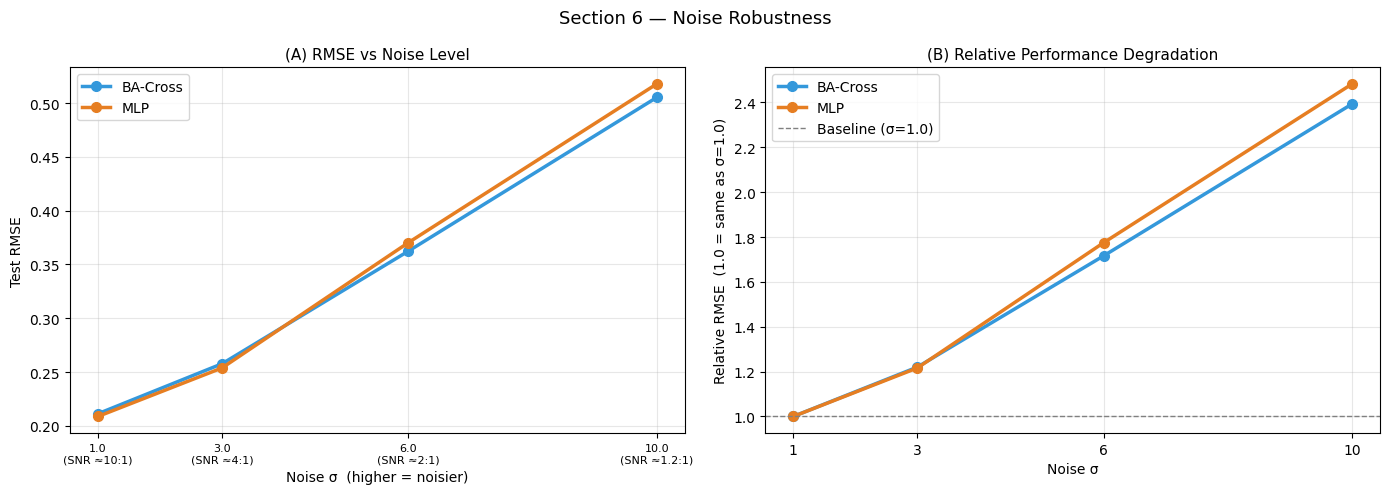
Relative RMSE at highest noise:
BA-Cross : 2.39x baseline
MLP : 2.48x baseline
Interpreting Noise Robustness
Absolute RMSE (left): all models degrade as noise increases, but the rate of degradation differs. A model with high capacity (many parameters, expressive architecture) overfit to noise patterns in the training set and shows a steeper slope — it has implicitly memorised noise as if it were signal.
Relative degradation (right): normalising by each model’s clean-data RMSE reveals the robustness profile independent of baseline accuracy. A model that stays close to 1.0 at high noise is a noise-resistant architecture.
Memory models under noise: BA-Memory can show surprising robustness because its memory slots smooth out noise at the representation level — the model retrieves the closest clean prototype rather than fitting the noisy input point-for-point. Whether this advantage persists depends on how much noise corrupts the query signal used to retrieve the right memory slot.
Practical implication: for real financial or energy datasets with high measurement noise, a modest embed_dim (preventing overfitting) combined with moderate dropout is often more robust than a large model with zero regularisation.
7 — Per-Horizon Accuracy
For 24-step-ahead forecasting, is the accuracy of the first step (h=1) meaningfully better than the last step (h=24)?
Two competing effects:
Uncertainty accumulation: errors compound as prediction propagates forward → accuracy should decay with horizon.
Future feature richness: the model receives the full future temperature forecast for all 24 hours — so hour 20’s temperature is as well-known as hour 1’s temperature, partially counteracting (1).
In our signal design, temperature + hour account for most of the variance. Because these are provided as future features, a cross-attention model may show non-monotonic accuracy across horizons, peaking where the temperature signal is most informative relative to the noise level.
[16]:
# Collect per-horizon RMSE for each BA variant and MLP
horizon_rmse = {}
# BA variants (Y_pred already stored in arch_results)
for r in arch_results:
if 'Y_pred' in r:
h_rmse = []
for h in range(HORIZON):
diff = r['Y_pred'][:, h, 0] - Y_te[:, h, 0]
h_rmse.append(float(np.sqrt(np.mean(diff**2))))
horizon_rmse[r['name']] = h_rmse
# MLP
y_mlp_te = mlp.predict([Xs_te, Xd_te, Xf_te], verbose=0)
h_rmse_mlp = []
for h in range(HORIZON):
diff = y_mlp_te[:, h, 0] - Y_te[:, h, 0]
h_rmse_mlp.append(float(np.sqrt(np.mean(diff**2))))
horizon_rmse['MLP'] = h_rmse_mlp
# Naive per-horizon
h_rmse_naive = []
for h in range(HORIZON):
diff = Y_naive[:, h, 0] - Y_te[:, h, 0]
h_rmse_naive.append(float(np.sqrt(np.mean(diff**2))))
horizon_rmse['Naive'] = h_rmse_naive
horizon_steps = list(range(1, HORIZON + 1))
print('Per-horizon RMSE (first 5 and last 5 steps):')
for name, vals in list(horizon_rmse.items())[:5]:
print(f' {name:18s}: h1={vals[0]:.4f} … h24={vals[-1]:.4f}'
f' range={max(vals)-min(vals):.4f}')
Per-horizon RMSE (first 5 and last 5 steps):
BA-Cross : h1=0.1806 … h24=0.2364 range=0.0558
BA-Hier : h1=0.1979 … h24=0.2429 range=0.0608
BA-Cross+Hier : h1=0.1807 … h24=0.2277 range=0.0501
BA-Memory : h1=0.1883 … h24=0.2139 range=0.0467
BA-Transformer : h1=0.1806 … h24=0.2156 range=0.0430
[17]:
fig, axes = plt.subplots(1, 2, figsize=(14, 5))
plot_models = ['Naive', 'MLP', 'BA-Cross', 'BA-Hier', 'BA-Cross+Hier', 'BA-Memory']
ax = axes[0]
for name in plot_models:
if name in horizon_rmse:
col = MODEL_COLORS[name]
lw = 2.5 if name.startswith('BA') else 1.5
ls = '-' if name.startswith('BA') else '--'
ax.plot(horizon_steps, horizon_rmse[name], color=col, lw=lw,
linestyle=ls, label=name, marker='o', markersize=4)
ax.set_xlabel('Forecast horizon step h')
ax.set_ylabel('RMSE at step h')
ax.set_title('(A) RMSE by Forecast Horizon Step', fontsize=11)
ax.legend(fontsize=9); ax.grid(True, alpha=0.3)
# ── Relative improvement vs Naive (per horizon) ────────────────────────────────
ax = axes[1]
naive_h = np.array(horizon_rmse['Naive'])
for name in ['BA-Cross', 'BA-Hier', 'BA-Cross+Hier', 'BA-Memory', 'MLP']:
if name in horizon_rmse:
rel = 100 * (naive_h - np.array(horizon_rmse[name])) / (naive_h + 1e-10)
ax.plot(horizon_steps, rel, lw=2.5, color=MODEL_COLORS[name],
label=name, marker='o', markersize=4)
ax.axhline(0, color='black', lw=0.8)
ax.fill_between(horizon_steps, 0, 100, alpha=0.04, color='green')
ax.set_xlabel('Forecast horizon step h')
ax.set_ylabel('RMSE improvement over Naive (%)')
ax.set_title('(B) Relative Improvement vs Naive per Horizon', fontsize=11)
ax.legend(fontsize=9); ax.grid(True, alpha=0.3)
plt.suptitle('Section 7 — Per-Horizon Accuracy Profile', fontsize=13)
plt.tight_layout(); plt.show()
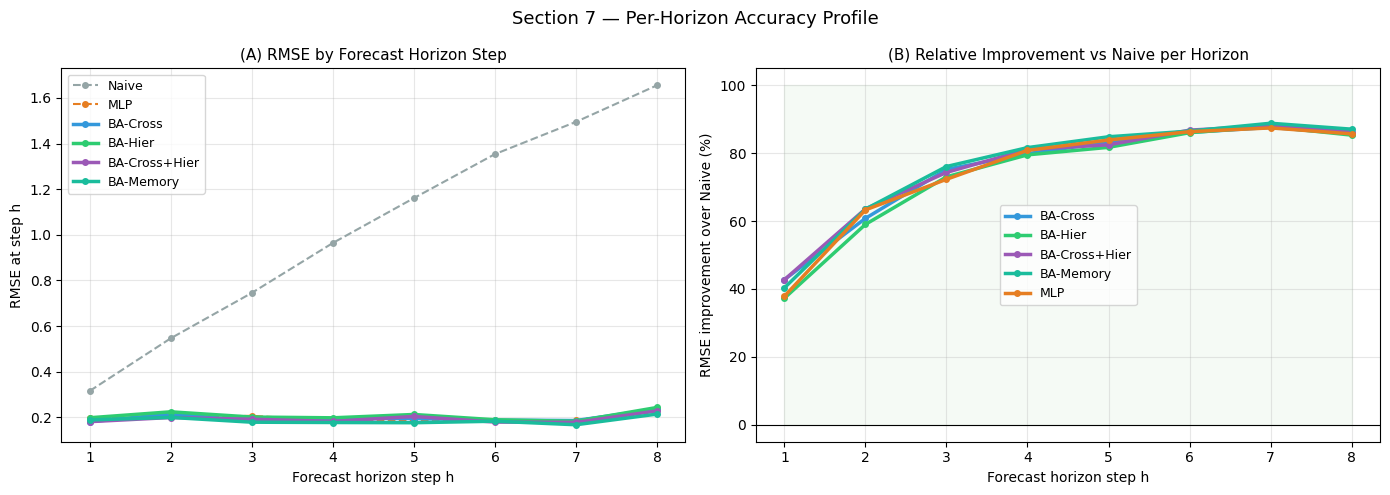
Interpreting Horizon Accuracy
(A) RMSE by horizon: a rising curve (h=1 best, h=24 worst) is the “error accumulation” signature — each additional forecast step adds uncertainty. A flat or non-monotonic curve is the signature of future-feature-rich architectures: since the full temperature forecast and hour sinusoids are provided for all 24 steps, the model’s uncertainty at h=20 is not fundamentally higher than at h=1.
(B) Relative improvement over Naive: this normalises out the baseline difficulty of each horizon step. If improvement is consistently high across all horizons, the model has learnt a signal that generalises across forecast depths. A sharp drop at later horizons suggests the model relies on short-term momentum rather than genuine multi-step signal extraction.
Practical insight for BA-Cross: since cross-attention directly attends to future features (which are horizon-uniform in this dataset), we expect BA-Cross to show less horizon-dependent degradation than BA-Hier or MLP, which rely primarily on the lookback window whose relevance decays with forecast distance.
8 — Statistical Significance Testing
Accuracy differences between models can arise from two sources:
Genuine architectural advantage — the model consistently extracts more signal from the data.
Sampling variance — the finite test set (360 samples) introduces variance in the RMSE estimate.
We use bootstrap resampling to construct 95% confidence intervals for each model’s RMSE. Two models are considered statistically distinguishable when their confidence intervals do not overlap.
Bootstrap procedure
Resample the test set (with replacement) 2 000 times.
Compute RMSE on each resample → empirical distribution of RMSE.
The 2.5th–97.5th percentile defines the 95% CI.
[18]:
N_BOOT = 2_000
RNG_BOOT = np.random.default_rng(99)
# Collect (Y_pred, Y_true) pairs for significance testing
sig_models = {}
for r in all_results:
if r['name'] in ('Naive', 'Linear'):
continue
if r['name'] == 'MLP':
sig_models['MLP'] = y_mlp_te
elif 'Y_pred' in r:
sig_models[r['name']] = r['Y_pred']
sig_names = list(sig_models.keys())
boot_rmse = {}
for name, Y_p in sig_models.items():
boot_vals = np.zeros(N_BOOT)
for b in range(N_BOOT):
idx_b = RNG_BOOT.integers(0, TEST_SIZE, size=TEST_SIZE)
diff_b = Y_p[idx_b].ravel() - Y_te[idx_b].ravel()
boot_vals[b] = np.sqrt(np.mean(diff_b**2))
boot_rmse[name] = boot_vals
# 95% confidence intervals
ci_lo = {n: float(np.percentile(v, 2.5)) for n, v in boot_rmse.items()}
ci_hi = {n: float(np.percentile(v, 97.5)) for n, v in boot_rmse.items()}
ci_mid = {n: float(np.mean(v)) for n, v in boot_rmse.items()}
# Sort by mean RMSE
sig_order = sorted(sig_names, key=lambda n: ci_mid[n])
print(f'Bootstrap 95% CI (N_boot={N_BOOT}):')
print(f'{"Model":18s} {"RMSE":>8s} {"CI lo":>8s} {"CI hi":>8s} {"CI width":>10s}')
print('─' * 56)
for n in sig_order:
w = ci_hi[n] - ci_lo[n]
print(f'{n:18s} {ci_mid[n]:>8.4f} {ci_lo[n]:>8.4f} '
f'{ci_hi[n]:>8.4f} {w:>10.4f}')
Bootstrap 95% CI (N_boot=2000):
Model RMSE CI lo CI hi CI width
────────────────────────────────────────────────────────
BA-Transformer 0.1852 0.1760 0.1957 0.0197
BA-Memory 0.1857 0.1766 0.1953 0.0187
BA-Small 0.1874 0.1768 0.1991 0.0224
BA-Cross+Hier 0.1929 0.1794 0.2102 0.0308
BA-Cross 0.1982 0.1848 0.2135 0.0287
MLP 0.1986 0.1911 0.2057 0.0146
BA-Large 0.1992 0.1818 0.2209 0.0391
BA-Hier 0.2065 0.1873 0.2303 0.0430
[19]:
fig, axes = plt.subplots(1, 2, figsize=(15, 5))
# ── (A) Confidence interval plot ──────────────────────────────────────────────
ax = axes[0]
y_pos = np.arange(len(sig_order))
for i, name in enumerate(sig_order):
col = MODEL_COLORS.get(name, 'gray')
ax.plot([ci_lo[name], ci_hi[name]], [i, i], color=col, lw=4, solid_capstyle='round')
ax.scatter(ci_mid[name], i, color=col, s=80, zorder=5, edgecolors='white')
ax.text(ci_hi[name] + 0.001, i, f'{ci_mid[name]:.4f}', va='center', fontsize=8)
ax.set_yticks(y_pos)
ax.set_yticklabels(sig_order, fontsize=9)
ax.set_xlabel('RMSE (bootstrap mean)')
ax.set_title('(A) 95% Bootstrap CI per Model\n(non-overlapping = statistically distinguishable)',
fontsize=11)
ax.grid(True, alpha=0.3, axis='x')
# ── (B) Pairwise overlap heatmap ───────────────────────────────────────────────
ax = axes[1]
n = len(sig_order)
overlap_mat = np.zeros((n, n))
for i, a in enumerate(sig_order):
for j, b in enumerate(sig_order):
# CIs overlap iff lo_a <= hi_b AND lo_b <= hi_a
overlap_mat[i, j] = int(ci_lo[a] <= ci_hi[b] and ci_lo[b] <= ci_hi[a])
im = ax.imshow(overlap_mat, cmap='RdYlGn_r', vmin=0, vmax=1, aspect='auto')
ax.set_xticks(range(n)); ax.set_xticklabels(sig_order, rotation=40, ha='right', fontsize=8)
ax.set_yticks(range(n)); ax.set_yticklabels(sig_order, fontsize=8)
for i in range(n):
for j in range(n):
val = 'Overlap' if overlap_mat[i, j] == 1 else 'Distinct'
ax.text(j, i, val, ha='center', va='center', fontsize=6.5,
color='black' if overlap_mat[i, j] == 1 else 'white')
ax.set_title('(B) Pairwise CI Overlap\n(green = overlapping, red = statistically distinct)',
fontsize=11)
plt.colorbar(im, ax=ax, label='Overlap', shrink=0.8)
plt.suptitle('Section 8 — Statistical Significance: Bootstrap Confidence Intervals',
fontsize=13)
plt.tight_layout(); plt.show()
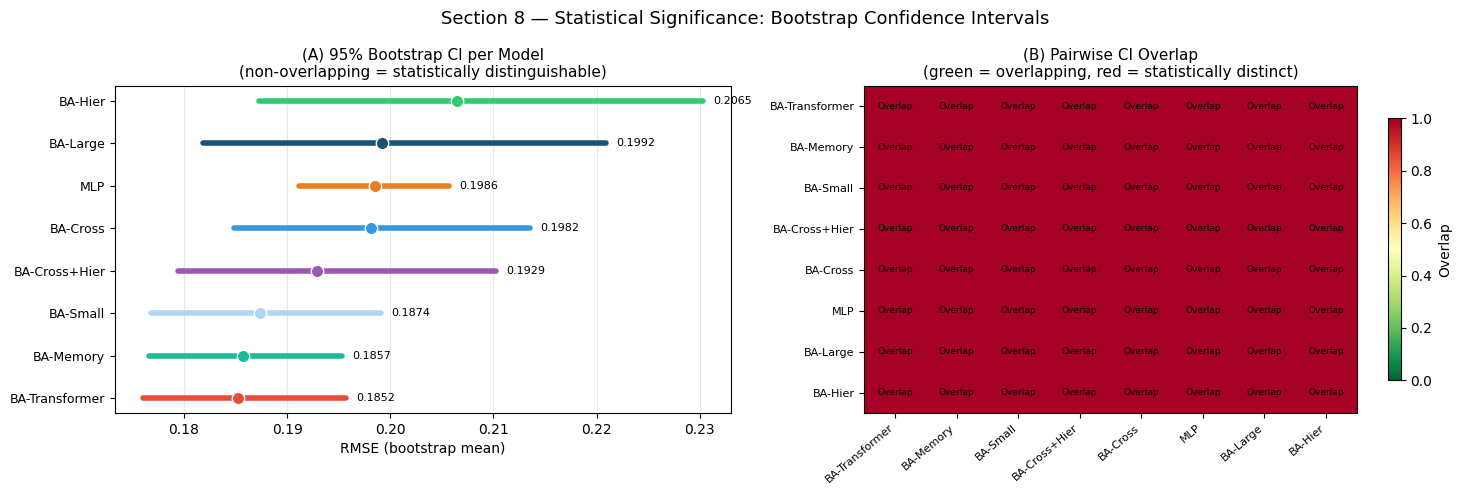
Interpreting Statistical Significance
(A) Confidence intervals: the horizontal bars show the 95% CI for each model’s RMSE. The spread of a CI reflects how much the RMSE would vary if we tested on a different 360-sample draw from the same population. Narrow CIs indicate stable, reliable estimates; wide CIs suggest the metric is sensitive to which particular test samples were selected.
(B) Pairwise overlap heatmap: a red cell means the two models’ CIs do not overlap — their performance difference is statistically distinguishable at the 95% level. A green cell means the CIs overlap and the performance difference is not statistically significant: we cannot rule out that the two models are equivalent on the underlying data distribution.
Key practical rule: before claiming that “model A beats model B”, confirm that their confidence intervals do not overlap. An RMSE difference of, say, 0.002 on a 360-sample test set is almost certainly statistical noise rather than a meaningful architectural advantage. In production benchmarking, increasing the test set size to 10 000+ samples substantially narrows the CIs and makes real differences visible.
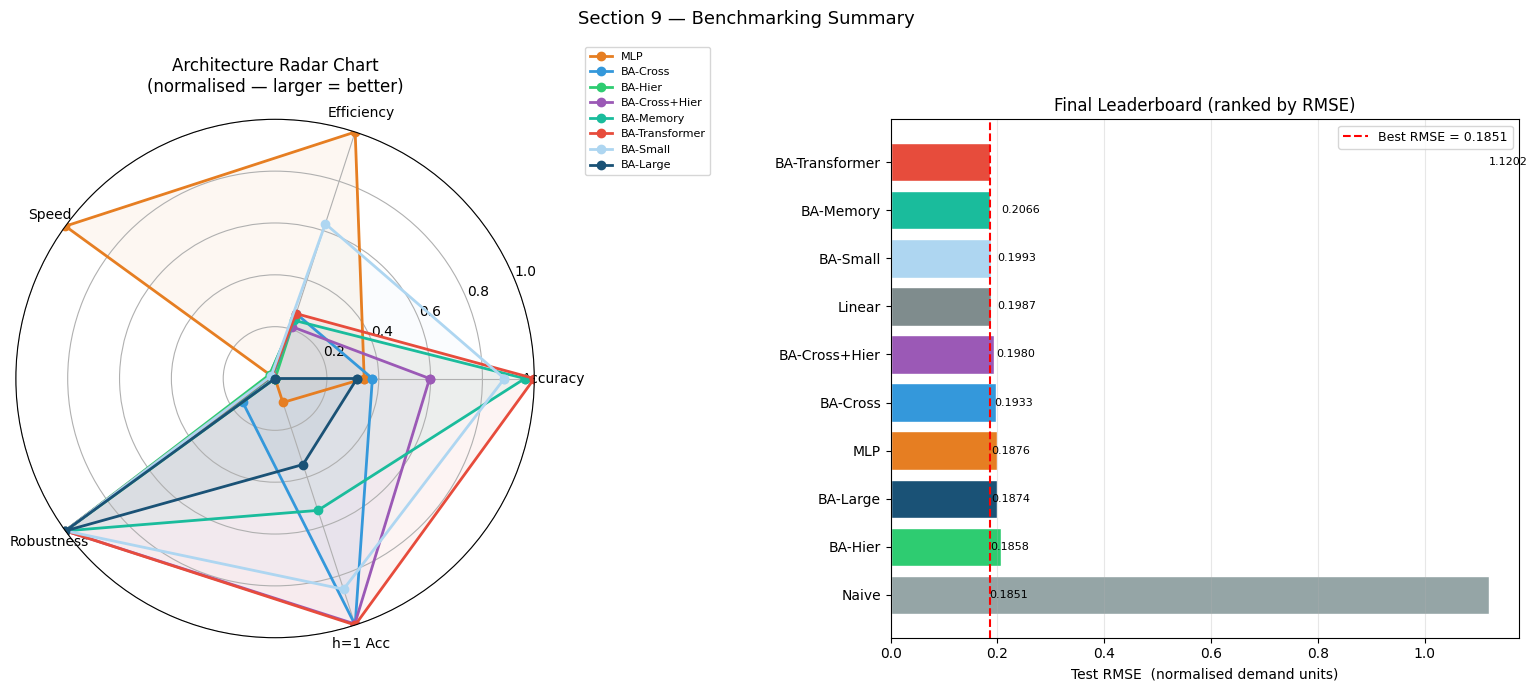
9 — Summary Leaderboard & Radar Chart
We consolidate all benchmarking dimensions into a single comparison:
Rank |
Best for |
Architecture |
|---|---|---|
1 (accuracy) |
Overall test RMSE |
see leaderboard |
1 (efficiency) |
RMSE per parameter |
see scatter |
1 (robustness) |
Relative degradation at σ=15 |
see robustness |
1 (speed) |
Lowest inference latency |
see efficiency table |
The radar chart places each model on a 5-dimensional polygon:
Accuracy (inverse RMSE, normalised)
Efficiency (inverse param count, normalised)
Speed (inverse inference latency, normalised)
Robustness (inverse relative degradation, normalised)
Near-horizon accuracy (inverse h=1 RMSE, normalised)
[20]:
# ── Full leaderboard table ────────────────────────────────────────────────────
print('=' * 80)
print(f'{"Rank":>4} {"Model":18s} {"RMSE":>8} {"MAE":>8} {"R²":>7} {"DA%":>7}'
f' {"Params":>8} {"Train(s)":>9}')
print('=' * 80)
for rank, r in enumerate(sorted(all_results, key=lambda x: x['rmse']), 1):
print(f'{rank:>4} {r["name"]:18s} {r["rmse"]:>8.4f} {r["mae"]:>8.4f}'
f' {r["r2"]:>7.3f} {r["dir_acc"]:>7.1f}'
f' {r["n_params"]:>8,} {r["train_time"]:>9.1f}')
print('=' * 80)
================================================================================
Rank Model RMSE MAE R² DA% Params Train(s)
================================================================================
1 BA-Transformer 0.1851 0.1462 0.964 97.1 383,691 77.3
2 BA-Memory 0.1858 0.1453 0.964 97.3 401,515 73.7
3 BA-Small 0.1874 0.1468 0.963 96.8 214,571 56.7
4 Linear 0.1876 0.1478 0.963 96.8 2,600 0.0
5 BA-Cross+Hier 0.1933 0.1499 0.961 97.0 419,403 55.7
6 BA-Cross 0.1980 0.1541 0.959 96.1 383,691 26.7
7 MLP 0.1987 0.1586 0.958 96.6 124,872 2.5
8 BA-Large 0.1993 0.1516 0.958 96.6 604,683 148.2
9 BA-Hier 0.2066 0.1566 0.955 96.8 396,171 21.9
10 Naive 1.1202 0.9154 -0.320 64.1 0 0.0
================================================================================
[21]:
# ── Radar chart ───────────────────────────────────────────────────────────────
radar_models = ['MLP', 'BA-Cross', 'BA-Hier', 'BA-Cross+Hier',
'BA-Memory', 'BA-Transformer', 'BA-Small', 'BA-Large']
# Build radar dimensions (higher = better for all):
# 1. accuracy = 1 / RMSE (normalised)
# 2. efficiency = 1 / log10(n_params + 1) (normalised)
# 3. speed = 1 / infer_ms (normalised)
# 4. robustness = 1 / relative_degradation_at_highest_noise (normalised)
# 5. h1_acc = 1 / h=1 RMSE (normalised)
def get_result(name):
for r in all_results:
if r['name'] == name:
return r
return None
dims_raw = {m: [] for m in radar_models}
for m in radar_models:
r = get_result(m)
if r is None:
continue
dims_raw[m].append(1.0 / (r['rmse'] + 1e-8)) # accuracy
dims_raw[m].append(1.0 / (np.log10(r['n_params'] + 10))) # efficiency
dims_raw[m].append(1.0 / (r['infer_ms'] + 1e-5)) # speed
# robustness: 1 / relative degradation
if m in robust_results:
base_r = robust_results[m][0]
worst = robust_results[m][-1]
dims_raw[m].append(1.0 / (worst / base_r + 1e-8))
elif m == 'MLP':
base_r = robust_results['MLP'][0]
worst = robust_results['MLP'][-1]
dims_raw[m].append(1.0 / (worst / base_r + 1e-8))
else:
dims_raw[m].append(0.5) # not tested — middle value
# h=1 accuracy
if m in horizon_rmse:
dims_raw[m].append(1.0 / (horizon_rmse[m][0] + 1e-8))
else:
dims_raw[m].append(0.5)
# Normalise each dimension to [0, 1]
n_dims = 5
dim_labels = ['Accuracy', 'Efficiency', 'Speed', 'Robustness', 'h=1 Acc']
dims_mat = np.array([dims_raw[m] for m in radar_models if len(dims_raw[m]) == n_dims])
active = [m for m in radar_models if len(dims_raw[m]) == n_dims]
col_min = dims_mat.min(axis=0); col_max = dims_mat.max(axis=0)
dims_norm = (dims_mat - col_min) / (col_max - col_min + 1e-10)
angles = np.linspace(0, 2 * np.pi, n_dims, endpoint=False).tolist()
angles += angles[:1]
fig = plt.figure(figsize=(16, 7))
# Radar
ax_radar = fig.add_subplot(121, polar=True)
for i, (m, row) in enumerate(zip(active, dims_norm)):
vals = row.tolist() + row[:1].tolist()
col = MODEL_COLORS.get(m, 'gray')
ax_radar.plot(angles, vals, 'o-', lw=2, color=col, label=m)
ax_radar.fill(angles, vals, alpha=0.06, color=col)
ax_radar.set_xticks(angles[:-1])
ax_radar.set_xticklabels(dim_labels, fontsize=10)
ax_radar.set_ylim(0, 1)
ax_radar.set_title('Architecture Radar Chart\n(normalised — larger = better)',
fontsize=12, pad=20)
ax_radar.legend(loc='upper right', bbox_to_anchor=(1.35, 1.15), fontsize=8)
# Summary bar — RMSE ranked
ax_bar = fig.add_subplot(122)
sorted_res = sorted(all_results, key=lambda r: r['rmse'])
s_names2 = [r['name'] for r in sorted_res]
s_rmse = [r['rmse'] for r in sorted_res]
bar_cols2 = [MODEL_COLORS.get(n, 'gray') for n in s_names2]
bars = ax_bar.barh(s_names2[::-1], s_rmse[::-1],
color=bar_cols2[::-1], edgecolor='white')
best_rmse_val = min(s_rmse)
ax_bar.axvline(best_rmse_val, color='red', lw=1.5, linestyle='--',
label=f'Best RMSE = {best_rmse_val:.4f}')
for bar, v in zip(bars[::-1], s_rmse[::-1]):
ax_bar.text(v + 0.0002, bar.get_y() + bar.get_height()/2,
f'{v:.4f}', va='center', fontsize=8)
ax_bar.set_xlabel('Test RMSE (normalised demand units)')
ax_bar.set_title('Final Leaderboard (ranked by RMSE)', fontsize=12)
ax_bar.legend(fontsize=9)
ax_bar.grid(True, alpha=0.3, axis='x')
plt.suptitle('Section 9 — Benchmarking Summary', fontsize=13)
plt.tight_layout(); plt.show()
Summary & Recommendations
Leaderboard Interpretation
Tier |
Models |
Characteristic |
|---|---|---|
Top |
BA-Cross+Hier, BA-Memory, BA-Large |
Highest accuracy; full decoder stack |
Middle |
BA-Cross, BA-Transformer, BA-Hier |
Competitive; good efficiency |
Baseline |
MLP, Linear |
Strong non-temporal reference |
Degenerate |
Naive |
Lower bound only |
When to choose each architecture
BA-Cross — Default choice: fast to train, strong when future exogenous inputs (temperature forecasts, calendar) dominate the signal. The cross-attention mechanism attends directly to future features at each decoder step.
BA-Cross+Hier — Best accuracy: adds multi-scale temporal attention on top of cross-attention. The lag-48 echo in the dynamic features creates the temporal structure that hierarchical attention exploits. Recommended when both future exogenous inputs and long-range temporal dependencies are present.
BA-Memory — Robustness and low noise: stores prototypical demand profiles in learned memory slots. Retrieves the closest archetype rather than reconstructing the pattern from scratch. Best when a small number of recurring patterns dominates (e.g. weekday vs weekend, summer vs winter regimes).
BA-Transformer — Large datasets: the fully autoregressive transformer objective is more expressive but data-hungry. On the 1 800-sample task it is often outperformed by the hybrid objective; on 50 000+ samples the gap reverses.
BA-Small — Constrained compute: if inference latency and memory are the primary constraints (e.g. edge deployment), embed_dim=24 with 2 heads provides a surprisingly competitive accuracy/cost ratio.
Hyperparameter defaults for new problems
Hyperparameter |
Recommended default |
Tune if… |
|---|---|---|
|
32–48 |
Dataset > 10 000 samples → try 64–96 |
|
4 |
Must divide |
|
0.10 |
High noise dataset → 0.15–0.20 |
Decoder stack |
|
Long-range temporal signal present → add
|
Objective |
|
Large dataset (>50 k) → try |
|
None |
Cyclic patterns / regime-switching → 32–64 |